This chapter explains the features, technical details and syntaxes of the C++ programming language. I assume that you could write some simple programs. Otherwise, read "Introduction To C++ Programming for Novices and First-time Programmers".
To be a proficient programmer, you need to master two things: (1) the syntax of the programming language, and (2) the core libraries (i.e., API) associated with the language.
Introduction to C++
C++ Standards
C++ is standardized as ISO/IEC 14882. Currently, there are two versions:
- C++98 (ISO/IEC 14882:1998): First standard version of C++.
- C++03 (ISO/IEC 14882:2003): minor "bug-fix" to C++98 with no change to the language. Commonly refer to as C++98/C++03 or First C++ standard.
- C++11 (ISO/IEC 14882:2011): Second standard version of C++. Informally called C++0x, as it was expected to finalize in 200x but was not released until 2011. It adds some new features to the language; more significantly, it greatly extends the C++ standard library and standard template library (STL).
- C++14: Informally called C++1y, is a small extension to C++11, with bug fixes and small improvement.
- C++17: informally called C++1z.
- C++2a: the next planned standard in 2020.
C++ Features
- C++ is C. C++ supports (almost) all the features of C. Like C, C++ allows programmers to manage the memory directly, so as to develop efficient programs.
- C++ is OO. C++ enhances the procedural-oriented C language with the object-oriented extension. The OO extension facilitates design, reuse and maintenance for complex software.
- Template C++. C++ introduces generic programming, via the so-called template. You can apply the same algorithm to different data types.
- STL. C++ provides a huge set of reusable standard libraries, in particular, the Standard Template Library (STL).
C++ Strength and Pitfall
C++ is a powerful language for high-performance applications, including writing operating systems and their subsystems, games and animation. C++ is also a complex and difficult programming language, which is really not meant for dummies. For example, to effectively use the C++ Standard Template Library (STL), you need to understand these difficult concepts: pointers, references, operator overloading and template, on top of the object-oriented programming concepts such as classes and objects, inheritance and polymorphism; and the traditional constructs such as decision and loop. C++ is performance centric. The C++ compiler does not issue warning/error message for many obvious programming mistakes, undefined and unspecified behaviors, such as array index out of range, using an uninitialized variable, etc, due to the focus on performance and efficiency rather than the ease of use - it assumes that those who choose to program in C++ are not dummies.
Basic Syntaxes
Revision
Below is a simple C++ program that illustrates the important programming constructs (sequential flow, while-loop, and if-else) and input/output. Read "Introduction To C++ Programming for Novices and First-time Programmers" if you need help in understanding this program.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
/* * Sum the odd and even numbers, respectively, from 1 to a given upperbound. * Also compute the absolute difference. * (SumOddEven.cpp) */ #include <iostream> // Needed to use IO functions using namespace std; int main() { int sumOdd = 0; // For accumulating odd numbers, init to 0 int sumEven = 0; // For accumulating even numbers, init to 0 int upperbound; // Sum from 1 to this upperbound int absDiff; // The absolute difference between the two sums // Prompt user for an upperbound cout << "Enter the upperbound: "; cin >> upperbound; // Use a while-loop to repeatedly add 1, 2, 3,..., to the upperbound int number = 1; while (number <= upperbound) { if (number % 2 == 0) { // Even number sumEven += number; // Add number into sumEven } else { // Odd number sumOdd += number; // Add number into sumOdd } ++number; // increment number by 1 } // Compute the absolute difference between the two sums if (sumOdd > sumEven) { absDiff = sumOdd - sumEven; } else { absDiff = sumEven - sumOdd; } // Print the results cout << "The sum of odd numbers is " << sumOdd << endl; cout << "The sum of even numbers is " << sumEven << endl; cout << "The absolute difference is " << absDiff << endl; return 0; } |
Enter the upperbound: 1000 The sum of odd numbers is 250000 The sum of even numbers is 250500 The absolute difference is 500
Program Notes
using namespace std;
The names cout and endl belong to the std namespace. They can be referenced via fully qualified name std::cout and std::endl, or simply as cout and endl with a "using namespace std;" statement. For simplicity, I shall use the latter approach in this section. I will discuss the significance later.
return 0;
The return value of 0 indicates normal termination; while non-zero (typically 1) indicates abnormal termination. C++ compiler will automatically
insert a "return 0;" at the end of the the main() function, thus, it statement can be omitted.
Instead of using numeric value of zero and non-zero, you can also use EXIT_SUCCESS or EXIT_FAILURE, which is defined in the cstdlib header (i.e., you need to "#include <cstdlib>".
Comments
Comments are used to document and explain your codes and program logic. Comments are not programming statements and are ignored by the compiler, but they VERY IMPORTANT for providing documentation and explanation for others to understand your program (and also for yourself three days later).
There are two kinds of comments in C/C++:
- Multi-line Comment: begins with a
/*and ends with a*/, and can span several lines. - End-of-line Comment: begins with
//and lasts till the end of the current line.
You should use comments liberally to explain and document your codes. During program development, instead of deleting a chunk of statements permanently, you could comment-out these statements so that you could get them back later, if needed.
Statements and Blocks
Statement: A programming statement is the smallest independent unit in a program, just like a sentence in the English language. It performs a piece of programming action. A programming statement must be terminated by a semi-colon (;), just like an English sentence ends with a period. (Why not ends with a period like an english sentence? This is because period crashes with decimal point - it is hard for the dumb computer to differentiate between period and decimal point!)
For examples,
// Each of the following lines is a programming statement, which ends with a semi-colon (;)
int number1 = 10;
int number2, number3 = 99;
int product;
product = number1 * number2 * number3;
cout << "Hello" << endl;
Block: A block (or a compound statement) is a group of statements surrounded by braces { }. All the statements inside the block is treated as one unit. Blocks are used as the body in constructs like function, if-else and loop, which may contain multiple statements but are treated as one unit. There is no need to put a semi-colon after the closing brace to end a complex statement. Empty block (without any statement) is permitted. For examples,
// Each of the followings is a "complex" statement comprising one or more blocks of statements.
// No terminating semi-colon needed after the closing brace to end the "complex" statement.
// Take note that a "complex" statement is usually written over a few lines for readability.
if (mark >= 50) {
cout << "PASS" << endl;
cout << "Well Done!" << endl;
cout << "Keep it Up!" << endl;
}
if (number == 88) {
cout << "Got it" << endl;
} else {
cout << "Try Again" << endl;
}
i = 1;
while (i < 8) {
cout << i << endl;
++i;
}
int main() {
...statements...
}
White Spaces and Formatting Source Codes
White Spaces: Blank, tab and new-line are collectively called white spaces. C++, like most of the computing languages, ignores extra white spaces. That is, multiple contiguous white spaces are treated as a single white space.
You need to use a white space to separate two keywords or tokens, e.g.,
int sum=0; // Need a white space between int and sum double average; // Need a white space between double and average average=sum/100.0;
Additional white spaces and extra lines are, however, ignored, e.g.,
// same as above
int sum
= 0 ;
double average ;
average = sum / 100.0;
Formatting Source Codes: As mentioned, extra white spaces are ignored and have no computational significance. However, proper indentation (with tabs and blanks) and extra empty lines greatly improves the readability of the program, which is extremely important for others (and yourself three days later) to understand your programs. For example, the following hello-world works, but can you understand the program?
#include <iostream>
using namespace std;int main(){cout<<"Hello, world!"<<endl;return 0;}
Braces: Place the beginning brace at the end of the line, and align the ending brace with the start of the statement.
Indentation: Indent the body of a block by an extra 3 (or 4 spaces), according to its level.
For example,
/* * Recommended Programming style. */ #include <iostream> using namespace std; // blank line to separate sections of codes int main() { // Place the beginning brace at the end of the current line // Indent the body by an extra 3 or 4 spaces for each level int mark = 70; if (mark >= 50) { // in level-1 block, indent once cout << "You Pass!" << endl; // in level-2 block, indent twice } else { cout << "You Fail!" << endl; } return 0; } // ending brace aligned with the start of the statement
Most IDEs (such as CodeBlocks, Eclipse and NetBeans) have a command to re-format your source code automatically.
Note: Traditional C-style formatting places the beginning and ending braces on the same column. For example,
/* * Traditional C-style. */ #include <iostream> using namespace std; int main() { if (mark >= 50) // in level-1 block, indent once { cout << "You Pass!" << endl; // in level-2 block, indent twice } else { cout << "You Fail!" << endl; } }
Preprocessor Directives
C++ source code is pre-processed before it is compiled into object code (as illustrated).

A preprocessor directive, which begins with a # sign (such as #include, #define), tells the preprocessor to perform a certain action (such as including a header file, or performing text replacement), before compiling the source code into object code. Preprocessor directives are not programming statements, and therefore should NOT be terminated with a semi-colon. For example,
#include <iostream> // To include the IO library header #include <cmath> // To include the Math library header #define PI 3.14159265 // To substitute the term PI with 3.14159265 in this file // DO NOT terminate preprocessor directive with a semi-colon
In almost all of the C++ programs, we use #include <iostream> to include the input/output stream library header into our program, so as to use the IO library function to carry out input/output operations (such as cin and cout).
More on preprocessor directives later.
Variables and Types
Variables
Computer programs manipulate (or process) data. A variable is used to store a piece of data for processing. It is called variable because you can change the value stored.
More precisely, a variable is a named storage location, that stores a value of a particular data type. In other words, a variable has a name, a type and stores a value.
- A variable has a name (or identifier), e.g.,
radius,area,age,height. The name is needed to uniquely identify each variable, so as to assign a value to the variable (e.g.,radius=1.2), and retrieve the value stored (e.g.,area = radius*radius*3.1416). - A variable has a type. Examples of type are,
int: for integers (whole numbers) such as123and-456;double: for floating-point or real numbers such as3.1416,-55.66, having a decimal point and fractional part.
- A variable can store a value of that particular type. It is important to take note that a variable in most programming languages is associated with a type, and can only store value of the particular type. For example, a
intvariable can store an integer value such as123, but NOT real number such as12.34, nor texts such as"Hello". - The concept of type was introduced into the early programming languages to simplify interpretation of data made up of 0s and 1s. The type determines the size and layout of the data, the range of its values, and the set of operations that can be applied.
The following diagram illustrates two types of variables: int and double. An int variable stores an integer (whole number). A double variable stores a real number.

Identifiers
An identifier is needed to name a variable (or any other entity such as a function or a class). C++ imposes the following rules on identifiers:
- An identifier is a sequence of characters, of up to a certain length (compiler-dependent, typically 255 characters), comprising uppercase and lowercase letters
(a-z, A-Z), digits(0-9), and underscore"_". - White space (blank, tab, new-line) and other special characters (such as
+,-,*,/,@,&, commas, etc.) are not allowed. - An identifier must begin with a letter or underscore. It cannot begin with a digit. Identifiers beginning with an underscore are typically reserved for system use.
- An identifier cannot be a reserved keyword or a reserved literal (e.g.,
int,double,if,else,for). - Identifiers are case-sensitive. A
roseis NOT aRose, and is NOT aROSE.
Caution: Programmers don't use blank character in names. It is either not supported, or will pose you more challenges.
Variable Naming Convention
A variable name is a noun, or a noun phrase made up of several words. The first word is in lowercase, while the remaining words are initial-capitalized, with no spaces between words. For example, thefontSize, roomNumber, xMax, yMin, xTopLeft and thisIsAVeryLongVariableName. This convention is also known as camel-case.
Recommendations
- It is important to choose a name that is self-descriptive and closely reflects the meaning of the variable, e.g.,
numberOfStudentsornumStudents. - Do not use meaningless names like
a,b,c,d,i,j,k,i1,j99. - Avoid single-alphabet names, which is easier to type but often meaningless, unless they are common names like
x,y,zfor coordinates,ifor index. - It is perfectly okay to use long names of says 30 characters to make sure that the name accurately reflects its meaning!
- Use singular and plural nouns prudently to differentiate between singular and plural variables. For example, you may use the variable
rowto refer to a single row number and the variablerowsto refer to many rows (such as an array of rows - to be discussed later).
Variable Declaration
To use a variable in your program, you need to first "introduce" it by declaring its name and type, in one of the following syntaxes:
| Syntax | Example |
|---|---|
// Declare a variable of a specified type type identifier; // Declare multiple variables of the same type, separated by commas type identifier-1, identifier-2, ..., identifier-n; // Declare a variable and assign an initial value type identifier = value; // Declare multiple variables with initial values type identifier-1 = value-1, ..., identifier-n = value-n; |
int option; double sum, difference, product, quotient; int magicNumber = 88; double sum = 0.0, product = 1.0; |
Example,
int mark1; // Declare an int variable called mark1 mark1 = 76; // Use mark1 int mark2; // Declare int variable mark2 mark2 = mark1 + 10; // Use mark2 and mark1 double average; // Declare double variable average average = (mark1 + mark2) / 2.0; // Use average, mark1 and mark2 int mark1; // Error: Declare twice mark2 = "Hello"; // Error: Assign value of a different type
Take note that:
- In C++, you need to declare the name of a variable before it can be used.
- C++ is a "strongly-type" language. A variable takes on a type. Once the type of a variable is declared, it can only store a value belonging to this particular type. For example, an
intvariable can hold only integer such as123, and NOT floating-point number such as-2.17or text string such as"Hello". The concept of type was introduced into the early programming languages to simplify interpretation of data made up of 0s and 1s. Knowing the type of a piece of data greatly simplifies its interpretation and processing. - Each variable can only be declared once.
- In C++, you can declare a variable anywhere inside the program, as long as it is declared before used. (In C prior to C99, all the variables must be declared at the beginning of functions.) It is recommended that your declare a variable just before it is first used.
- The type of a variable cannot be changed inside the program.
CAUTION: Uninitialized Variables
When a variable is declared, it contains garbage until you assign an initial value. It is important to take note that C/C++ does not issue any warning/error if you use a variable before initialize it - which certainly leads to some unexpected results. For example,
1 2 3 4 5 6 7 8 9 |
#include <iostream>
using namespace std;
int main() {
int number; // Declared but not initialized
cout << number << endl; // Used before initialized
// No warning/error, BUT unexpected result
return 0;
}
|
Constants (const)
Constants are non-modifiable variables, declared with keyword const. Their values cannot be changed during program execution. Also, const must be initialized during declaration. For examples:
const double PI = 3.1415926; // Need to initialize
Constant Naming Convention: Use uppercase words, joined with underscore. For example, MIN_VALUE, MAX_SIZE.
Expressions
An expression is a combination of operators (such as addition '+', subtraction '-', multiplication '*', division '/') and operands (variables or literal values), that can be evaluated to yield a single value of a certain type. For example,
1 + 2 * 3 // give int 7 int sum, number; sum + number // evaluated to an int value double principal, interestRate; principal * (1 + interestRate) // evaluated to a double value
Assignment (=)
An assignment statement:
- assigns a literal value (of the RHS) to a variable (of the LHS); or
- evaluates an expression (of the RHS) and assign the resultant value to a variable (of the LHS).
The RHS shall be a value; and the LHS shall be a variable (or memory address).
The syntax for assignment statement is:
| Syntax | Example |
|---|---|
// Assign the literal value (of the RHS) to the variable (of the LHS) variable = literal-value; // Evaluate the expression (RHS) and assign the result to the variable (LHS) variable = expression; |
number = 88; sum = sum + number; |
The assignment statement should be interpreted this way: The expression on the right-hand-side (RHS) is first evaluated to produce a resultant value (called rvalue or right-value). The rvalue is then assigned to the variable on the left-hand-side (LHS) (or lvalue, which is a location that can hold a rvalue). Take note that you have to first evaluate the RHS, before assigning the resultant value to the LHS. For examples,
number = 8; // Assign literal value of 8 to the variable number number = number + 1; // Evaluate the expression of number + 1, // and assign the resultant value back to the variable number
The symbol "=" is known as the assignment operator. The meaning of "=" in programming is different from Mathematics. It denotes assignment instead of equality. The RHS is a literal value; or an expression that evaluates to a value; while the LHS must be a variable. Note that x = x + 1 is valid (and often used) in programming. It evaluates x + 1 and assign the resultant value to the variable x. x = x + 1 illegal in Mathematics. While x + y = 1 is allowed in Mathematics, it is invalid in programming (because the LHS of an assignment statement must be a variable). Some programming languages use symbol ":=", "←", "->", or "→" as the assignment operator to avoid confusion with equality.
Fundamental Types
Integers: C++ supports these integer types: char, short, int, long, long long (in C++11) in a non-decreasing order of size. The actual size depends on the implementation. The integers (except char) are signed number (which can hold zero, positive and negative numbers). You could use the keyword unsigned [char|short|int|long|long long] to declare an unsigned integers (which can hold zero and positive numbers). There are a total 10 types of integers - signed|unsigned combined with char|short|int|long|long long.
Characters: Characters (e.g., 'a', 'Z', '0', '9') are encoded in ASCII into integers, and kept in type char. For example, character '0' is 48 (decimal) or 30H (hexadecimal); character 'A' is 65 (decimal) or 41H (hexadecimal); character 'a' is 97 (decimal) or 61H (hexadecimal). Take note that the type char can be interpreted as character in ASCII code, or an 8-bit integer. Unlike int or long, which is signed, char could be signed or unsigned, depending on the implementation. You can use signed char or unsigned char to explicitly declare signed or unsigned char.
Floating-point Numbers: There are 3 floating point types: float, double and long double, for single, double and long double precision floating point numbers. float and double are represented as specified by IEEE 754 standard. A float can represent a number between ±1.40239846×10^-45 and ±3.40282347×10^38, approximated. A double can represented a number between ±4.94065645841246544×10^-324 and ±1.79769313486231570×10^308, approximated. Take note that not all real numbers can be represented by float and double, because there are infinite real numbers. Most of the values are approximated.
Boolean Numbers: A special type called bool (for boolean), which takes a value of either true or false.
The table below shows the typical size, minimum, maximum for the primitive types. Again, take note that the sizes are implementation dependent.
| Category | Type | Description | Bytes (Typical) |
Minimum (Typical) |
Maximum (Typical) |
|---|---|---|---|---|---|
| Integers | int (or signed int) |
Signed integer (of at least 16 bits) | 4 (2) | -2147483648 | 2147483647 |
| unsigned int | Unsigned integer (of at least 16 bits) | 4 (2) | 0 | 4294967295 | |
| char | Character (can be either signed or unsigned depends on implementation) |
1 | |||
| signed char | Character or signed tiny integer (guarantee to be signed) |
1 | -128 | 127 | |
| unsigned char | Character or unsigned tiny integer (guarantee to be unsigned) |
1 | 0 | 255 | |
| short (or short int) (or signed short) (or signed short int) |
Short signed integer (of at least 16 bits) | 2 | -32768 | 32767 | |
| unsigned short (or unsigned shot int) |
Unsigned short integer (of at least 16 bits) | 2 | 0 | 65535 | |
| long (or long int) (or signed long) (or signed long int) |
Long signed integer (of at least 32 bits) | 4 (8) | -2147483648 | 2147483647 | |
| unsigned long (or unsigned long int) |
Unsigned long integer (of at least 32 bits) | 4 (8) | 0 | same as above | |
| long long (or long long int) (or signed long long) (or signed long long int) (C++11) |
Very long signed integer (of at least 64 bits) | 8 | -263 | 263-1 | |
| unsigned long long (or unsigned long long int) (C++11) |
Unsigned very long integer (of at least 64 bits) | 8 | 0 | 264-1 | |
| Real Numbers | float | Floating-point number, ≈7 digits (IEEE 754 single-precision floating point format) |
4 | 3.4e38 | 3.4e-38 |
| double | Double precision floating-point number, ≈15 digits (IEEE 754 double-precision floating point format) |
8 | 1.7e308 | 1.7e-308 | |
| long double | Long double precision floating-point number, ≈19 digits (IEEE 754 quadruple-precision floating point format) |
12 (8) | |||
| Boolean Numbers |
bool | Boolean value of either true or false |
1 | false (0) | true (1 or non-zero) |
| Wide Characters |
wchar_t char16_t (C++11) char32_t (C++11) |
Wide (double-byte) character | 2 (4) |
In addition, many C++ library functions use a type called size_t, which is equivalent (typedef) to a unsigned int, meant for counting, size or length, with 0 and positive integers.
*The sizeof Operator
C/C++ provides an unary sizeof operator to get the size of the operand (in bytes). The following program uses sizeof operator to print the size of the fundamental types.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
/*
* Print Size of Fundamental Types (SizeofTypes.cpp).
*/
#include <iostream>
using namespace std;
int main() {
cout << "sizeof(char) is " << sizeof(char) << " bytes " << endl;
cout << "sizeof(short) is " << sizeof(short) << " bytes " << endl;
cout << "sizeof(int) is " << sizeof(int) << " bytes " << endl;
cout << "sizeof(long) is " << sizeof(long) << " bytes " << endl;
cout << "sizeof(long long) is " << sizeof(long long) << " bytes " << endl;
cout << "sizeof(float) is " << sizeof(float) << " bytes " << endl;
cout << "sizeof(double) is " << sizeof(double) << " bytes " << endl;
cout << "sizeof(long double) is " << sizeof(long double) << " bytes " << endl;
cout << "sizeof(bool) is " << sizeof(bool) << " bytes " << endl;
return 0;
}
|
sizeof(char) is 1 bytes sizeof(short) is 2 bytes sizeof(int) is 4 bytes sizeof(long) is 4 bytes sizeof(long long) is 8 bytes sizeof(float) is 4 bytes sizeof(double) is 8 bytes sizeof(long double) is 12 bytes sizeof(bool) is 1 bytes
The results may vary among different systems.
*Header <climits>
The climits header (ported to C++ from C's limits.h) contains information about limits of integer type. For example,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
/* Test integer limits in <climits> header */ #include <iostream> #include <climits> // integer limits using namespace std; int main() { cout << "int max = " << INT_MAX << endl; cout << "int min = " << INT_MIN << endl; cout << "unsigned int max = " << UINT_MAX << endl; cout << "long long max = " << LLONG_MAX << endl; cout << "long long min = " << LLONG_MIN << endl; cout << "unsigned long long max = " << ULLONG_MAX << endl; cout << "Bits in char = " << CHAR_BIT << endl; cout << "char max = " << CHAR_MAX << endl; cout << "char min = " << CHAR_MIN << endl; cout << "signed char max = " << SCHAR_MAX << endl; cout << "signed char min = " << SCHAR_MIN << endl; cout << "unsigned char max = " << UCHAR_MAX << endl; return 0; } |
int max = 2147483647 int min = -2147483648 unsigned int max = 4294967295 long long max = 9223372036854775807 long long min = -9223372036854775808 unsigned long long max = 18446744073709551615 Bits in char = 8 char max = 127 char min = -128 signed char max = 127 signed char min = -128 unsigned char max = 255
Again, the outputs depend on the system.
The minimum of unsigned integer is always 0. The other constants are SHRT_MAX, SHRT_MIN, USHRT_MAX, LONG_MIN, LONG_MAX, ULONG_MAX. Try inspecting this header (search for climits under your compiler).
*Header <cfloat>
Similarly, the cfloat header (ported from C's float.h) contain information on limits for floating point numbers, such as minimum number of significant digits (FLT_DIG, DBL_DIG, LDBL_DIG for float, double and long double), number of bits for mantissa (FLT_MANT_DIG, DBL_MANT_DIG, LDBL_MANT_DIG), maximum and minimum exponent values, etc. Try inspecting this header (search for cfloat under your compiler).
*Header <limits>
The climits and cfloat headers are ported over from C's limit.h and float.h. C++ added a new header called limits.
[TODO]
Choosing Types
As a programmer, you need to choose variables and decide on the type of the variables to be used in your programs. Most of the times, the decision is intuitive. For example, use an integer type for counting and whole number; a floating-point type for number with fractional part, char for a single character, and boolean for binary outcome.
Rule of Thumb
- Use
intfor integer anddoublefor floating point numbers. Usebyte,short,longandfloatonly if you have a good reason to choose that specific precision. - Use
int(orunsigned int) for counting and indexing, NOT floating-point type (floatordouble). This is because integer type are precise and more efficient in operations. - Use an integer type if possible. Use a floating-point type only if the number contains a fractional part.
Read my article on "Data Representation" if you wish to understand how the numbers and characters are represented inside the computer memory. In brief, It is important to take note that char '1' is different from int 1, short 1, float 1.0, double 1.0, and String "1". They are represented differently in the computer memory, with different precision and interpretation. For example, short 1 is "00000000 00000001", int 1 is "00000000 00000000 00000000 00000001", long long 1 is "00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001", float 1.0 is "0 01111111 0000000 00000000 00000000", double 1.0 is "0 01111111111 0000 00000000 00000000 00000000 00000000 00000000 00000000", char '1' is "00110001".
There is a subtle difference between int 0 and double 0.0.
Furthermore, you MUST know the type of a value before you can interpret a value. For example, this value "00000000 00000000 00000000 00000001" cannot be interpreted unless you know the type.
*The typedef Statement
Typing "unsigned int" many time can get annoying. The typedef statement can be used to create a new name for an existing type. For example, you can create a new type called "uint" for "unsigned int" as follow. You should place the typedef immediately after #include. Use typedef with care because it makes the program hard to read and understand.
typedef unsigned int uint;
Many C/C++ compilers define a type called size_t, which is a typedef of unsigned int.
typedef unsigned int size_t;
Literals for Fundamental Types and String
A literal is a specific constant value, such as 123, -456, 3.14, 'a', "Hello", that can be assigned directly to a variable; or used as part of an expression. They are called literals because they literally and explicitly identify their values.
Integer Literals
A whole number, such as 123 and -456, is treated as an int, by default. For example,
int number = -123; int sum = 4567; int bigSum = 8234567890; // ERROR: this value is outside the range of int
An int literal may precede with a plus (+) or minus (-) sign, followed by digits. No commas or special symbols (e.g., $ or space) is allowed (e.g., 1,234 and $123 are invalid). No preceding 0 is allowed too (e.g., 007 is invalid).
Besides the default base 10 integers, you can use a prefix '0' (zero) to denote a value in octal, prefix '0x' for a value in hexadecimal, and prefix '0b' for binary value (in some compilers), e.g.,
int number1 = 1234; // Decimal int number2 = 01234; // Octal 1234, Decimal 2322 int number3 = 0x1abc; // hexadecimal 1ABC, decimal 15274 int number4 = 0b10001001; // binary (may not work in some compilers)
A long literal is identified by a suffix 'L' or 'l' (avoid lowercase, which can be confused with the number one). A long long int is identified by a suffix 'LL'. You can also use suffix 'U' for unsigned int, 'UL' for unsigned long, and 'ULL' for unsigned long long int. For example,
long number = 12345678L; // Suffix 'L' for long long sum = 123; // int 123 auto-casts to long 123L long long bigNumber = 987654321LL; // Need suffix 'LL' for long long int
No suffix is needed for short literals. But you can only use integer values in the permitted range. For example,
short smallNumber = 1234567890; // ERROR: this value is outside the range of short. short midSizeNumber = -12345;
Floating-point Literals
A number with a decimal point, such as 55.66 and -33.44, is treated as a double, by default. You can also express them in scientific notation, e.g., 1.2e3, -5.5E-6, where e or E denotes the exponent in power of 10. You could precede the fractional part or exponent with a plus (+) or minus (-) sign. Exponent shall be an integer. There should be no space or other characters (e.g., space) in the number.
You MUST use a suffix of 'f' or 'F' for float literals, e.g., -1.2345F. For example,
float average = 55.66; // Error! RHS is a double. Need suffix 'f' for float. float average = 55.66f;
Use suffix 'L' (or 'l') for long double.
Character Literals and Escape Sequences
A printable char literal is written by enclosing the character with a pair of single quotes, e.g., 'z', '$', and '9'. In C++, characters are represented using 8-bit ASCII code, and can be treated as a 8-bit signed integers in arithmetic operations. In other words, char and 8-bit signed integer are interchangeable. You can also assign an integer in the range of [-128, 127] to a char variable; and [0, 255] to an unsigned char.
You can find the ASCII code table HERE.
For example,
char letter = 'a'; // Same as 97 char anotherLetter = 98; // Same as the letter 'b' cout << letter << endl; // 'a' printed cout << anotherLetter << endl; // 'b' printed instead of the number anotherLetter += 2; // 100 or 'd' cout << anotherLetter << endl; // 'd' printed cout << (int)anotherLetter << endl; // 100 printed
Non-printable and control characters can be represented by a so-called escape sequence, which begins with a back-slash (\). The commonly-used escape sequences are:
| Escape Sequence | Description | Hex (Decimal) |
|---|---|---|
| \n | New-line (or Line-feed) | 0AH (10D) |
| \r | Carriage-return | 0DH (13D) |
| \t | Tab | 09H (9D) |
| \" | Double-quote (needed to include " in double-quoted string) | 22H (34D) |
| \' | Single-quote | 27H (39D) |
| \\ | Back-slash (to resolve ambiguity) | 5CH (92D) |
Notes:
- New-line (
0AH) and carriage return (0dH), represented by\n, and\rrespectively, are used as line delimiter (or end-of-line, or EOL). However, take note that Unixes/Mac use\nas EOL, Windows use\r\n. - Horizontal Tab (
09H) is represented as\t. - To resolve ambiguity, characters back-slash (
\), single-quote (') and double-quote (") are represented using escape sequences\\,\'and\", respectively. This is because a single back-slash begins an escape sequence, while single-quotes and double-quotes are used to enclose character and string. - Other less commonly-used escape sequences are:
\?or?,\afor alert or bell,\bfor backspace,\ffor form-feed,\vfor vertical tab. These may not be supported in some consoles.
The <cctype> Header
The cctype header (ported from C's ctype.h) provides functions such as isalpha(), isdigit(), isspace(), ispunct(), isalnum(), isupper(), islower() to determine the type of character; and toupper(), tolower() for case conversion.
String Literals
A String literal is composed of zero of more characters surrounded by a pair of double quotes, e.g., "Hello, world!", "The sum is ", "". For example,
String directionMsg = "Turn Right";
String greetingMsg = "Hello";
String statusMsg = ""; // empty string
String literals may contains escape sequences. Inside a String, you need to use \" for double-quote to distinguish it from the ending double-quote, e.g. "\"quoted\"". Single quote inside a String does not require escape sequence. For example,
cout << "Use \\\" to place\n a \" within\ta\tstring" << endl;
Use \" to place a " within a string
TRY: Write a program to print the following picture. Take note that you need to use escape sequences to print special characters.
'__'
(oo)
+========\/
/ || %%% ||
* ||-----||
"" ""
bool Literals
There are only two bool literals, i.e., true and false. For example,
bool done = true;
bool gameOver = false;
int i;
if (i == 9) { // returns either true or false
......
}
In an expression, bool values and literals are converted to int 0 for false and 1 (or a non-zero value) for true.
Example (Literals)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
/* Testing Primitive Types (TestLiteral.cpp) */ #include <iostream> using namespace std; int main() { char gender = 'm'; // char is single-quoted bool isMarried = true; // true(non-zero) or false(0) unsigned short numChildren = 8; // [0, 255] short yearOfBirth = 1945; // [-32767, 32768] unsigned int salary = 88000; // [0, 4294967295] double weight = 88.88; // With fractional part float gpa = 3.88f; // Need suffix 'f' for float // "cout <<" can be used to print value of any type cout << "Gender is " << gender << endl; cout << "Is married is " << isMarried << endl; cout << "Number of children is " << numChildren << endl; cout << "Year of birth is " << yearOfBirth << endl; cout << "Salary is " << salary << endl; cout << "Weight is " << weight << endl; cout << "GPA is " << gpa << endl; return 0; } |
Gender is m
Is married is 1 // true
Number of children is 8
Year of birth is 1945
Salary is 88000
Weight is 88.88
GPA is 3.88
Operations
Arithmetic Operators
C++ supports the following arithmetic operators for numbers: short, int, long, long long, char (treated as 8-bit signed integer), unsigned short, unsigned int, unsigned long, unsigned long long, unsigned char, float, double and long double.
| Operator | Description | Usage | Examples |
|---|---|---|---|
| * | Multiplication | expr1 * expr2 | 2 * 3 → 6; 3.3 * 1.0 → 3.3 |
| / | Division | expr1 / expr2 | 1 / 2 → 0; 1.0 / 2.0 → 0.5 |
| % | Remainder (Modulus) | expr1 % expr2 | 5 % 2 → 1; -5 % 2 → -1 |
| + | Addition | expr1 + expr2 | 1 + 2 → 3; 1.1 + 2.2 → 3.3 |
| - | Subtraction | expr1 - expr2 | 1 - 2 → -1; 1.1 - 2.2 → -1.1 |
All the above operators are binary operators, i.e., they take two operands. The multiplication, division and remainder take precedence over addition and subtraction. Within the same precedence level (e.g., addition and subtraction), the expression is evaluated from left to right. For example, 1+2+3-4 is evaluated as ((1+2)+3)-4.
It is important to take note that int/int produces an int, with the result truncated, e.g., 1/2 → 0 (instead of 0.5).
Take note that C/C++ does not have an exponent (power) operator ('^' is exclusive-or, not exponent).
Arithmetic Expressions
In programming, the following arithmetic expression:
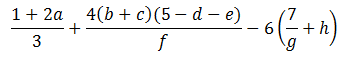
must be written as (1+2*a)/3 + (4*(b+c)*(5-d-e))/f - 6*(7/g+h). You cannot omit the multiplication symbol '*' (as in Mathematics).
Like Mathematics, the multiplication '*' and division '/' take precedence over addition '+' and subtraction '-'. Parentheses () have higher precedence. The operators '+', '-', '*', and '/' are left-associative. That is, 1 + 2 + 3 + 4 is treated as (((1+2) + 3) + 4).
Mixed-Type Operations
If both the operands of an arithmetic operation belong to the same type, the operation is carried out in that type, and the result belongs to that type. For example, int/int → int; double/double → double.
However, if the two operands belong to different types, the compiler promotes the value of the smaller type to the larger type (known as implicit type-casting). The operation is then carried out in the larger type. For example, int/double → double/double → double. Hence, 1/2 → 0, 1.0/2.0 → 0.5, 1.0/2 → 0.5, 1/2.0 → 0.5.
For example,
| Type | Example | Operation |
|---|---|---|
| int | 2 + 3 | int 2 + int 3 → int 5 |
| double | 2.2 + 3.3 | double 2.2 + double 3.3 → double 5.5 |
| mix | 2 + 3.3 | int 2 + double 3.3 → double 2.0 + double 3.3 → double 5.3 |
| int | 1 / 2 | int 1 / int 2 → int 0 |
| double | 1.0 / 2.0 | double 1.0 / double 2.0 → double 0.5 |
| mix | 1 / 2.0 | int 1 / double 2.0 → double 1.0 + double 2.0 → double 0.5 |
Example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
/* Testing mix-type arithmetic operations (TestMixTypeOp.cpp) */ #include <iostream> #include <iomanip> // needed for formatting floating-point numbers using namespace std; int main() { int i1 = 2, i2 = 4; double d1 = 2.5, d2 = 5.0; // Print floating-points in fixed format with 1 decimal place cout << fixed << setprecision(1); // need <iomanip> cout << i1 << " + " << i2 << " = " << i1+i2 << endl; // 6 cout << d1 << " + " << d2 << " = " << d1+d2 << endl; // 7.5 cout << i1 << " + " << d2 << " = " << i1+d2 << endl; // 7.0 <== cout << i1 << " - " << i2 << " = " << i1-i2 << endl; // -2 cout << d1 << " - " << d2 << " = " << d1-d2 << endl; // -2.5 cout << i1 << " - " << d2 << " = " << i1-d2 << endl; // -3.0 <== cout << i1 << " * " << i2 << " = " << i1*i2 << endl; // 8 cout << d1 << " * " << d2 << " = " << d1*d2 << endl; // 12.5 cout << i1 << " * " << d2 << " = " << i1*d2 << endl; // 10.0 <== cout << i1 << " / " << i2 << " = " << i1/i2 << endl; // 0 <== cout << d1 << " / " << d2 << " = " << d1/d2 << endl; // 0.5 cout << i1 << " / " << d2 << " = " << i1/d2 << endl; // 0.4 <== return 0; } |
Overflow/UnderFlow
Study the output of the following program:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
/* Test Arithmetic Overflow/Underflow (TestOverflow.cpp) */ #include <iostream> using namespace std; int main() { // Range of int is [-2147483648, 2147483647] int i1 = 2147483647; // max int cout << i1 + 1 << endl; // -2147483648 (overflow) cout << i1 + 2 << endl; // -2147483647 cout << i1 * i1 << endl; // 1 int i2 = -2147483648; // min int cout << i2 - 1 << endl; // 2147483647 (underflow) cout << i2 - 2 << endl; // 2147483646 cout << i2 * i2 << endl; // 0 return 0; } |
In arithmetic operations, the resultant value wraps around if it exceeds its range (i.e., overflow or underflow). C++ runtime does not issue an error/warning message but produces incorrect result.
It is important to take note that checking of overflow/underflow is the programmer's responsibility, i.e., your job!
This feature is an legacy design, where processors were slow. Checking for overflow/underflow consumes computation power and reduces performance.
To check for arithmetic overflow (known as secure coding) is tedious. Google for "INT32-C. Ensure that operations on signed integers do not result in overflow" @ www.securecoding.cert.org.
Compound Assignment Operators
Besides the usual simple assignment operator '=' described earlier, C++ also provides the so-called compound assignment operators as listed:
| Operator | Usage | Description | Example |
|---|---|---|---|
| = | var = expr | Assign the value of the LHS to the variable at the RHS | x = 5; |
| += | var += expr | same as var = var + expr | x += 5; same as x = x + 5 |
| -= | var -= expr | same as var = var - expr | x -= 5; same as x = x - 5 |
| *= | var *= expr | same as var = var * expr | x *= 5; same as x = x * 5 |
| /= | var /= expr | same as var = var / expr | x /= 5; same as x = x / 5 |
| %= | var %= expr | same as var = var % expr | x %= 5; same as x = x % 5 |
Increment/Decrement Operators
C++ supports these unary arithmetic operators: increment '++' and decrement '--'.
| Operator | Example | Result |
|---|---|---|
| ++ | x++; ++x | Increment by 1, same as x += 1 |
| -- | x--; --x | Decrement by 1, same as x -= 1 |
For example,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
/* Test on increment (++) and decrement (--) Operator (TestIncDec.cpp) */ #include <iostream> using namespace std; int main() { int mark = 76; // declare & assign cout << mark << endl; // 76 mark++; // increase by 1 (post-increment) cout << mark << endl; // 77 ++mark; // increase by 1 (pre-increment) cout << mark << endl; // 78 mark = mark + 1; // also increase by 1 (or mark += 1) cout << mark << endl; // 79 mark--; // decrease by 1 (post-decrement) cout << mark << endl; // 78 --mark; // decrease by 1 (pre-decrement) cout << mark << endl; // 77 mark = mark - 1; // also decrease by 1 (or mark -= 1) cout << mark << endl; // 76 return 0; } |
The increment/decrement unary operator can be placed before the operand (prefix operator), or after the operands (postfix operator). They takes on different meaning in operations.
| Operator | Description | Example | Result |
|---|---|---|---|
| ++var | Pre-Increment Increment var, then use the new value of var |
y = ++x; | same as x=x+1; y=x; |
| var++ | Post-Increment Use the old value of var, then increment var |
y = x++; | same as oldX=x; x=x+1; y=oldX; |
| --var | Pre-Decrement | y = --x; | same as x=x-1; y=x; |
| var-- | Post-Decrement | y = x--; | same as oldX=x; x=x-1; y=oldX; |
If '++' or '--' involves another operation, then pre- or post-order is important to specify the order of the two operations. For examples,
x = 5; cout << x++ << endl; // Save x (5); Increment x (=6); Print old x (5). x = 5; cout << ++x << endl; // Increment x (=6); Print x (6). // This is confusing! Try to avoid! What is i=++i? What is i=i++?
Prefix operator (e.g, ++i) could be more efficient than postfix operator (e.g., i++) in some situations.
Implicit Type-Conversion vs. Explicit Type-Casting
Converting a value from one type to another type is called type casting (or type conversion). There are two kinds of type casting:
- Implicit type-conversion performed by the compiler automatically, and
- Explicit type-casting via an unary type-casting operator in the form of
(new-type)operandornew-type(operand).
Implicit (Automatic) Type Conversion
When you assign a value of a fundamental (built-in) type to a variable of another fundamental type, C++ automatically converts the value to the receiving type, if the two types are compatible. For examples,
- If you assign an
intvalue to adoublevariable, the compiler automatically casts theintvalue to adoubledouble (e.g., from 1 to 1.0) and assigns it to thedoublevariable. - if you assign a
doublevalue of to anintvariable, the compiler automatically casts thedoublevalue to anintvalue (e.g., from 1.2 to 1) and assigns it to theintvariable. The fractional part would be truncated and lost. Some compilers issue a warning/error "possible loss in precision"; others do not.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
/* * Test implicit type casting (TestImplicitTypeCast.cpp) */ #include <iostream> #include <iomanip> using namespace std; int main() { int i; double d; // print floating point number in fixed format with 1 decimal place cout << fixed << setprecision(1); i = 3; d = i; // Assign an int value to double cout << "d = " << d << endl; // 3.0 d = 5.5; i = d; // Assign a double value to int cout << "i = " << i << endl; // 5 (truncated, no warning!) i = 6.6; // Assign a double literal to int cout << "i = " << i << endl; // 6 (truncated, no warning!) } |
C++ will not perform automatic type conversion, if the two types are not compatible.
Explicit Type-Casting
You can explicitly perform type-casting via the so-called unary type-casting operator in the form of (new-type)operand or new-type(operand). The type-casting operator takes one operand in the particular type, and returns an equivalent value in the new type. Take note that it is an operation that yields a resultant value, similar to an addition operation although addition involves two operands. For example,
// Print floating-point number in fixed format with 1 decimal point (need <iomanip>) cout << fixed << setprecision(1); cout << (double)5 << endl; // int 5 → double 5.0 cout << (int)5.5 << endl; // double 5.5 → int 5 double aDouble = 5.6; int anInt = (int)aDouble; // return 5 and assign to anInt. aDouble does not change! // C++ also supports function-style type cast. cout << double(5) << endl; // 5.0 cout << int(5.5) << endl; // 5 cout << int(aDouble) << endl; // 5
Example: Suppose that you want to find the average (in double) of the integers between 1 and 100. Study the following codes:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
/* * Testing Explicit Type Cast (Average1to100.cpp). */ #include <iostream> #include <iomanip> using namespace std; int main() { int sum = 0; double average; for (int number = 1; number <= 100; ++number) { sum += number; // Final sum is int 5050 } average = sum / 100; // Won't work (average = 50.0 instead of 50.5) cout << fixed << setprecision(1); cout << "Average is " << average << endl; // Average is 50.0 return 0; } |
You don't get the fractional part although the average is a double. This is because both the sum and 100 are int. The result of division is an int, which is then implicitly casted to double and assign to the double variable average. To get the correct answer, you can do either:
average = (double)sum / 100; // Cast sum from int to double before division average = sum / (double)100; // Cast 100 from int to double before division average = sum / 100.0; average = (double)(sum / 100); // Won't work. why? // C++ also support function-style type casting in the form of new-type(operand) average = double(sum) / 100; // Same as (double)sum / 100
Example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
/* Test Type Casting (TestTypeCast.cpp) */ #include <iostream> #include <iomanip> using namespace std; int main() { // Print floating-point number in fixed format with 1 decimal place cout << fixed << setprecision(1); // Test explicit type casting int i1 = 4, i2 = 8; cout << i1 / i2 << endl; // 0 cout << (double)i1 / i2 << endl; // 0.5 cout << i1 / (double)i2 << endl; // 0.5 cout << (double)(i1 / i2) << endl; // 0.0 double d1 = 5.5, d2 = 6.6; cout << (int)d1 / i2 << endl; // 0 cout << (int)(d1 / i2) << endl; // 0 // Test implicit type casting d1 = i1; // int implicitly casts to double cout << d1 << endl; // 4.0 i2 = d2; // double truncates to int! (Warning?) cout << i2 << endl; // 6 } |
Example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
/* * Converting between Celsius and Fahrenheit (ConvertTemperature.cpp) * Celsius = (5/9)(Fahrenheit–32) * Fahrenheit = (9/5)Celsius+32 */ #include <iostream> #include <iomanip> // needed for formatting floating-point numbers using namespace std; int main() { double celsius, fahrenheit; // Format floating-points in fixed with 2 decimal places cout << fixed << setprecision(2); cout << "Enter the temperature in celsius: "; cin >> celsius; fahrenheit = celsius*9/5 + 32; // 9/5*celsius + 32 gives wrong answer! Why? cout << celsius << "C is " << fahrenheit << "F" << endl; cout << "Enter the temperature in fahrenheit: "; cin >> fahrenheit; celsius = (fahrenheit - 32)*5/9; // 5/9*(fahrenheit - 32) gives wrong answer! Why? cout << fahrenheit << "F is " << celsius << "C" << endl; return 0; } |
*Operator static-cast<type>
C++ introduces a new operator called static_cast<type> to perform type conversion (because the regular cast mentioned earlier is too lax and could produce expected results). static_cast signal an error if conversion fails. For example,
double d = 5.5; int i = static_cast<int>(d); float f = static_cast<float>(i); long l = static_cast<logn>(d);
Relational and Logical Operators
Very often, you need to compare two values before deciding on the action to be taken, e.g., if mark is more than or equal to 50, print "PASS".
C++ provides six comparison operators (or relational operators):
| Operator | Description | Usage | Example (x=5, y=8) |
|---|---|---|---|
| == | Equal to | expr1 == expr2 | (x == y) → false |
| != | Not Equal to | expr1 != expr2 | (x != y) → true |
| > | Greater than | expr1 > expr2 | (x > y) → false |
| >= | Greater than or equal to | expr1 >= expr2 | (x >= 5) → true |
| < | Less than | expr1 < expr2 | (y < 8) → false |
| <= | Less than or equal to | expr1 >= expr2 | (y <= 8) → true |
In C++, these comparison operations returns a bool value of either false (0) or true (1 or a non-zero value).
Each comparison operation involves two operands, e.g., x <= 100. It is invalid to write 1 < x < 100 in programming. Instead, you need to break out the two comparison operations x > 1, x < 100, and join with with a logical AND operator, i.e., (x > 1) && (x < 100), where && denotes AND operator.
C++ provides four logical operators (which operate on boolean operands only):
| Operator | Description | Usage |
|---|---|---|
| && | Logical AND | expr1 && expr2 |
| || | Logical OR | expr1 || expr2 |
| ! | Logical NOT | !expr |
| ^ | Logical XOR | expr1 ^ expr2 |
The truth tables are as follows:
| AND (&&) | true | false |
|---|---|---|
| true | true | false |
| false | false | false |
| OR (||) | true | false |
|---|---|---|
| true | true | true |
| false | true | false |
| NOT (!) | true | false |
|---|---|---|
| false | true |
| XOR (^) | true | false |
|---|---|---|
| true | false | true |
| false | true | false |
Example:
// Return true if x is between 0 and 100 (inclusive) (x >= 0) && (x <= 100) // wrong to use 0 <= x <= 100 // Return true if x is outside 0 and 100 (inclusive) (x < 0) || (x > 100) //or !((x >= 0) && (x <= 100)) // Return true if year is a leap year // A year is a leap year if it is divisible by 4 but not by 100, or it is divisible by 400. ((year % 4 == 0) && (year % 100 != 0)) || (year % 400 == 0)
Exercise: Given the year, month (1-12), and day (1-31), write a boolean expression which returns true for dates before October 15, 1582 (Gregorian calendar cut over date).
Ans: (year < 1582) || (year == 1582 && month < 10) || (year == 1582 && month == 10 && day < 15)
Flow Control
There are three basic flow control constructs - sequential, conditional (or decision), and loop (or iteration), as illustrated below.
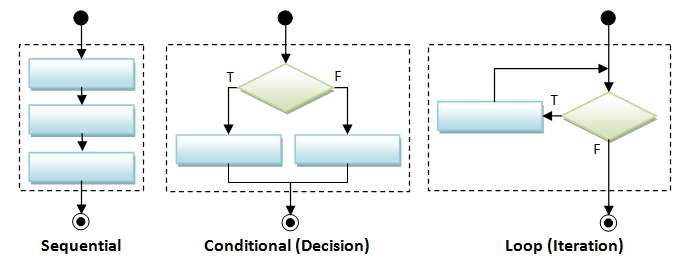
Sequential Flow Control
A program is a sequence of instructions. Sequential flow is the most common and straight-forward, where programming statements are executed in the order that they are written - from top to bottom in a sequential manner.
Conditional (Decision) Flow Control
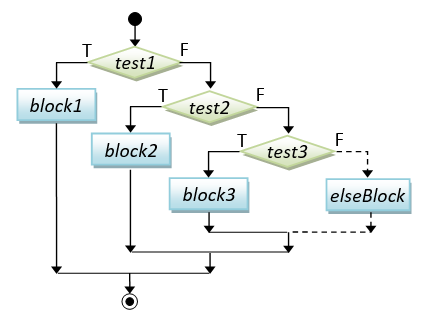
There are a few types of conditionals, if-then, if-then-else, nested-if (if-elseif-elseif-...-else), switch-case, and conditional expression.
| Syntax | Example | Flowchart |
|---|---|---|
// if-then
if ( booleanExpression ) {
true-block ;
}
|
if (mark >= 50) {
cout << "Congratulation!" << endl;
cout << "Keep it up!" << endl;
}
|
 |
// if-then-else
if ( booleanExpression ) {
true-block ;
} else {
false-block ;
}
|
if (mark >= 50) {
cout << "Congratulation!" << endl;
cout << "Keep it up!" << endl;
} else {
cout << "Try Harder!" << endl;
}
|
 |
// nested-if
if ( booleanExpr-1 ) {
block-1 ;
} else if ( booleanExpr-2 ) {
block-2 ;
} else if ( booleanExpr-3 ) {
block-3 ;
} else if ( booleanExpr-4 ) {
......
} else {
elseBlock ;
} |
if (mark >= 80) {
cout << "A" << endl;
} else if (mark >= 70) {
cout << "B" << endl;
} else if (mark >= 60) {
cout << "C" << endl;
} else if (mark >= 50) {
cout << "D" << endl;
} else {
cout << "F" << endl;
}
|
 |
// switch-case
switch ( selector ) {
case value-1:
block-1; break;
case value-2:
block-2; break;
case value-3:
block-3; break;
......
case value-n:
block-n; break;
default:
default-block;
} |
char oper; int num1, num2, result;
......
switch (oper) {
case '+':
result = num1 + num2; break;
case '-':
result = num1 - num2; break;
case '*':
result = num1 * num2; break;
case '/':
result = num1 / num2; break;
default:
cout << "Unknown operator" << endl;
} |
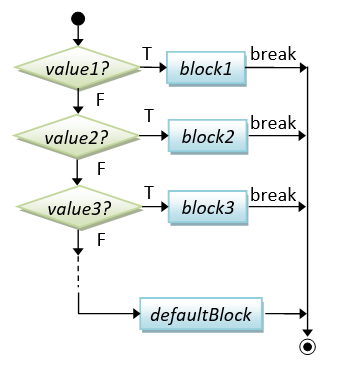 |
"switch-case" is an alternative to the "nested-if". In a switch-case statement, a break statement is needed for each of the cases. If break is missing, execution will flow through the following case. You can use either an int or char variable as the case-selector.
Conditional Operator: A conditional operator is a ternary (3-operand) operator, in the form of booleanExpr ? trueExpr : falseExpr. Depending on the booleanExpr, it evaluates and returns the value of trueExpr or falseExpr.
| Syntax | Example |
|---|---|
booleanExpr ? trueExpr : falseExpr |
cout << (mark >= 50) ? "PASS" : "FAIL" << endl; // return either "PASS" or "FAIL", and put to cout max = (a > b) ? a : b; // RHS returns a or b abs = (a > 0) ? a : -a; // RHS returns a or -a |
Braces: You could omit the braces { }, if there is only one statement inside the block. For example,
if (mark >= 50) cout << "PASS" << endl; // Only one statement, can omit { } but not recommended else { // more than one statements, need { } cout << "FAIL" << endl; cout << "Try Harder!" << endl; }
However, I recommend that you keep the braces, even though there is only one statement in the block, to improve the readability of your program.
Exercises
[TODO]
Loop Flow Control
Again, there are a few types of loops: for-loop, while-do, and do-while.
| Syntax | Example | Flowchart |
|---|---|---|
// for-loop
for (init; test; post-proc) {
body ;
}
|
// Sum from 1 to 1000
int sum = 0;
for (int number = 1; number <= 1000; ++number) {
sum += number;
}
|
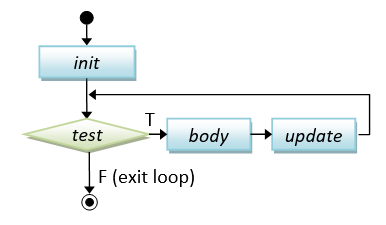 |
// while-do
while ( condition ) {
body ;
}
|
int sum = 0, number = 1;
while (number <= 1000) {
sum += number;
++number;
}
|
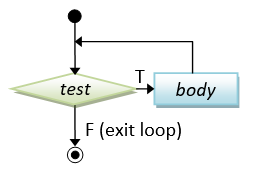 |
// do-while
do {
body ;
}
while ( condition ) ;
|
int sum = 0, number = 1;
do {
sum += number;
++number;
} while (number <= 1000);
|
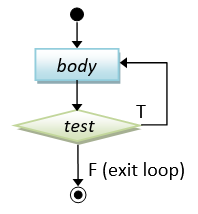 |
The difference between while-do and do-while lies in the order of the body and condition. In while-do, the condition is tested first. The body will be executed if the condition is true and the process repeats. In do-while, the body is executed and then the condition is tested. Take note that the body of do-while will be executed at least once (vs. possibly zero for while-do).
Suppose that your program prompts user for a number between 1 to 10, and checks for valid input, do-while with a boolean flag could be more appropriate.
// Input with validity check bool valid = false; int number; do { // prompt user to enter an int between 1 and 10 ...... // if the number entered is valid, set done to exit the loop if (number >=1 && number <= 10) { valid = true; } } while (!valid); // Need a semi-colon to terminate do-while
Below is an example of using while-do:
// Game loop bool gameOver = false; while (!gameOver) { // play the game ...... // Update the game state // Set gameOver to true if appropriate to exit the game loop ...... }
Example (Counter-Controlled Loop): Prompt user for an upperbound. Sum the integers from 1 to a given upperbound and compute its average.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
/* * Sum from 1 to a given upperbound and compute their average (SumNumbers.cpp) */ #include <iostream> using namespace std; int main() { int sum = 0; // Store the accumulated sum int upperbound; cout << "Enter the upperbound: "; cin >> upperbound; // Sum from 1 to the upperbound for (int number = 1; number <= upperbound; ++number) { sum += number; } cout << "Sum is " << sum << endl; cout << "Average is " << (double)sum / upperbound << endl; // Sum only the odd numbers int count = 0; // counts of odd numbers sum = 0; // reset sum for (int number=1; number <= upperbound; number=number+2) { ++count; sum += number; } cout << "Sum of odd numbers is " << sum << endl; cout << "Average is " << (double)sum / count << endl; } |
Example (Sentinel-Controlled Loop): Prompt user for positive integers, and display the count, maximum, minimum and average. Terminate when user enters -1.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
/* Prompt user for positive integers and display the count, maximum, minimum and average. Terminate the input with -1 (StatNumbers.cpp) */ #include <iostream> #include <climits> // for INT_MAX #include <iomanip> // for setprecision(n) using namespace std; int main() { int numberIn; // input number (positive integer) int count = 0; // count of inputs, init to 0 int sum = 0; // sum of inputs, init to 0 int max = 0; // max of inputs, init to minimum int min = INT_MAX; // min of inputs, init to maximum (need <climits>) int sentinel = -1; // Input terminating value // Read Inputs until sentinel encountered cout << "Enter a positive integer or " << sentinel << " to exit: "; while (cin >> numberIn && numberIn != sentinel) { // Check input for positive integer if (numberIn > 0) { ++count; sum += numberIn; if (max < numberIn) max = numberIn; if (min > numberIn) min = numberIn; } else { cout << "error: input must be positive! try again..." << endl; } cout << "Enter a positive integer or " << sentinel << " to exit: "; } // Print result cout << endl; cout << "Count is " << count << endl; if (count > 0) { cout << "Maximum is " << max << endl; cout << "Minimum is " << min << endl; cout << fixed << setprecision(2); // print floating point to 2 decimal places (need <iomanip>) cout << "Average is " << (double)sum / count << endl; } } |
Program Notes
- In computing, a sentinel value is a special value that indicates the end of data (e.g., a negative value to end a sequence of positive value, end-of-file, null character in the null-terminated string). In this example, we use -1 as the sentinel value to indicate the end of inputs, which is a sequence of positive integers. Instead of hardcoding the value of -1, we use a variable called
sentinelfor flexibility and ease-of-maintenance. - Take note of the while-loop pattern in reading the inputs. In this pattern, you need to repeat the prompting statement.
- To control the precision of floating point numbers, use:
cout << fixed << setprecision(n);
where n is the number of decimal places (after the decimal point). You need to include<iomanip>header. Thesetprecision()is sticky. That is, it will remain in effect until another value is set.
Exercises
[TODO]
Interrupting Loop Flow - "break" and "continue"
The break statement breaks out and exits the current (innermost) loop.
The continue statement aborts the current iteration and continue to the next iteration of the current (innermost) loop.
break and continue are poor structures as they are hard to read and hard to follow. Use them only if absolutely necessary. You can always write the same program without using break and continue.
Example (break): The following program lists the non-prime numbers between 2 and an upperbound.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
/* * List non-prime from 1 to an upperbound (NonPrimeList.cpp). */ #include <iostream> #include <cmath> using namespace std; int main() { int upperbound; cout << "Enter the upperbound: "; cin >> upperbound; for (int number = 2; number <= upperbound; ++number) { // Not a prime, if there is a factor between 2 and sqrt(number) int maxFactor = (int)sqrt(number); for (int factor = 2; factor <= maxFactor; ++factor) { if (number % factor == 0) { // Factor? cout << number << " "; break; // A factor found, no need to search for more factors } } } cout << endl; return 0; } |
Let's rewrite the above program to list all the primes instead. A boolean flag called isPrime is used to indicate whether the current number is a prime. It is then used to control the printing.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
/* * List primes from 1 to an upperbound (PrimeListWithBreak.cpp). */ #include <iostream> #include <cmath> using namespace std; int main() { int upperbound; cout << "Enter the upperbound: "; cin >> upperbound; for (int number = 2; number <= upperbound; ++number) { // Not a prime, if there is a factor between 2 and sqrt(number) int maxFactor = (int)sqrt(number); bool isPrime = true; // boolean flag to indicate whether number is a prime for (int factor = 2; factor <= maxFactor; ++factor) { if (number % factor == 0) { // Factor? isPrime = false; // number is not a prime break; // A factor found, no need to search for more factors } } if (isPrime) cout << number << " "; } cout << endl; return 0; } |
Let's rewrite the above program without using break statement. A while loop is used (which is controlled by the boolean flag) instead of for loop with break.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
/* * List primes from 1 to an upperbound (PrimeList.cpp). */ #include <iostream> #include <cmath> using namespace std; int main() { int upperbound; cout << "Enter the upperbound: "; cin >> upperbound; for (int number = 2; number <= upperbound; ++number) { // Not prime, if there is a factor between 2 and sqrt of number int maxFactor = (int)sqrt(number); bool isPrime = true; int factor = 2; while (isPrime && factor <= maxFactor) { if (number % factor == 0) { // Factor of number? isPrime = false; } ++factor; } if (isPrime) cout << number << " "; } cout << endl; return 0; } |
Example (continue):
// Sum 1 to upperbound, exclude 11, 22, 33,... int upperbound = 100; int sum = 0; for (int number = 1; number <= upperbound; ++number) { if (number % 11 == 0) continue; // Skip the rest of the loop body, continue to the next iteration sum += number; } // It is better to re-write the loop as: for (int number = 1; number <= upperbound; ++number) { if (number % 11 != 0) sum += number; }
Example (break and continue): Study the following program.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
/* A mystery series (Mystery.cpp) */
#include <iostream>
using namespace std;
int main() {
int number = 1;
while (true) {
++number;
if ((number % 3) == 0) continue;
if (number == 133) break;
if ((number % 2) == 0) {
number += 3;
} else {
number -= 3;
}
cout << number << " ";
}
cout << endl;
return 0;
}
|
Terminating Program
There are a few ways that you can terminate your program, before reaching the end of the programming statements.
exit(): You could invoke the function exit(int exitCode), in <cstdlib> (ported from C's "stdlib.h"), to terminate the program and return the control to the Operating System. By convention, return code of zero indicates normal termination; while a non-zero exitCode (-1) indicates abnormal termination. For example,
abort(): The header <cstdlib> also provide a function called abort(), which can be used to terminate the program abnormally.
if (errorCount > 10) {
cout << "too many errors" << endl;
exit(-1); // Terminate the program
// OR abort();
}
The "return" Statement: You could also use a "return returnValue" statement in the main() function to terminate the program and return control back to the Operating System.
For example,
int main() {
...
if (errorCount > 10) {
cout << "too many errors" << endl;
return -1; // Terminate and return control to OS from main()
}
...
}
Nested Loops
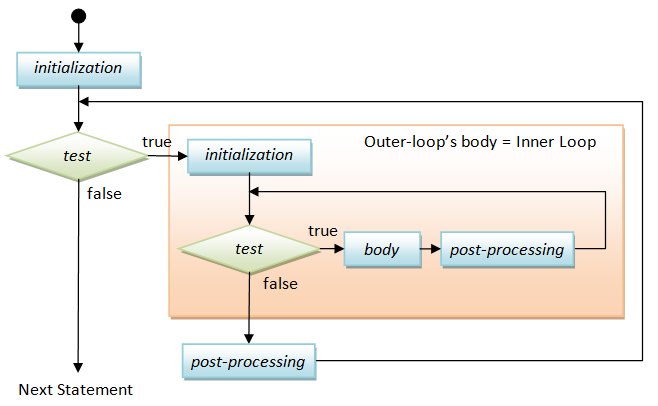
The following diagram illustrates a nested for-loop, i.e., an inner for-loop within an outer for-loop.
Try out the following program, which prints a 8-by-8 checker box pattern using nested loops, as follows:
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
/* * Print square pattern (PrintSquarePattern.cpp). */ #include <iostream> using namespace std; int main() { int size = 8; for (int row = 1; row <= size; ++row) { // Outer loop to print all the rows for (int col = 1; col <= size; ++col) { // Inner loop to print all the columns of each row cout << "# "; } cout << endl; // A row ended, bring the cursor to the next line } return 0; } |
This program contains two nested for-loops. The inner loop is used to print a row of eight "# ", which is followed by printing a newline. The outer loop repeats the inner loop to print all the rows.
Suppose that you want to print this pattern instead (in program called PrintCheckerPattern.cpp):
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
You need to print an additional space for even-number rows. You could do so by adding the following statement before Line 8.
if ((row % 2) == 0) { // print a leading space for even-numbered rows
cout << " ";
}
Exercises
- Print these patterns using nested loop (in a program called
PrintPattern1x). Use a variable calledsizefor the size of the pattern and try out various sizes. You should use as few printing statements as possible.# * # * # * # * # # # # # # # # # # # # # # # # 1 1 # * # * # * # * # # # # # # # # # # # # # # 2 1 1 2 # * # * # * # * # # # # # # # # # # # # 3 2 1 1 2 3 # * # * # * # * # # # # # # # # # # 4 3 2 1 1 2 3 4 # * # * # * # * # # # # # # # # 5 4 3 2 1 1 2 3 4 5 # * # * # * # * # # # # # # 6 5 4 3 2 1 1 2 3 4 5 6 # * # * # * # * # # # # 7 6 5 4 3 2 1 1 2 3 4 5 6 7 # * # * # * # * # # 8 7 6 5 4 3 2 1 1 2 3 4 5 6 7 8 (a) (b) (c) (d) (e)Hints:
The equations for major and opposite diagonals are row = col and row + col = size + 1. Decide on what to print above and below the diagonal. - Print the timetable of 1 to 9, as follows, using nested loop. (Hints: you need to use an if-else statement to check whether the product is single-digit or double-digit, and print an additional space if needed.)
1 2 3 4 5 6 7 8 9 2 4 6 8 10 12 14 16 18 ......
- Print these patterns using nested loop.
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # (a) (b) (c) (d) (e)
Some Issues in Flow Control
Dangling else: The "dangling else" problem can be illustrated as follows:
if (i == 0)
if (j == 0)
cout << "i and j are zero" << endl;
else cout << "i is not zero" << endl; // intend for the outer-if
The else clause in the above codes is syntactically applicable to both the outer-if and the inner-if. The C++ compiler always associate the else clause with the innermost if (i.e., the nearest if). Dangling else can be resolved by applying explicit parentheses. The above codes are logically incorrect and require explicit parentheses as shown below.
if ( i == 0) {
if (j == 0) cout << "i and j are zero" << endl;
} else {
cout << "i is not zero" << endl; // non-ambiguous for outer-if
}
Endless Loop: The following constructs:
while (true) { ...... }
is commonly used. It seems to be an endless loop (or infinite loop), but it is usually terminated via a break or return statement inside the loop body. This kind of code is hard to read - avoid if possible by re-writing the condition.
Exercises
[TODO]
Writing Correct and Good Programs
It is important to write programs that produce the correct results. It is also important to write programs that others (and you yourself three days later) can understand, so that the programs can be maintained - I call these programs good programs.
Here are the suggestions:
- Follow established convention so that everyone has the same basis of understanding.
- Format and layout of the source code with appropriate indents, white spaces and white lines. Use 3 or 4 spaces for indent, and blank lines to separate sections of codes.
- Choose good names that are self-descriptive and meaningful, e.g.,
row,col,size,xMax,numStudents. Do not use meaningless names, such asa,b,c,d. Avoid single-alphabet names (easier to type but often meaningless), except common names likes x,y,zfor co-ordinates andifor index. - Provide comments to explain the important as well as salient concepts. Comment your codes liberally.
- Write your program documentation while writing your programs.
- Avoid un-structured constructs, such as
breakandcontinue, which are hard to follow. - Use "mono-space" fonts (such as Consola, Courier New, Courier) for writing/displaying your program.
Programming Errors
There are generally three classes of programming errors:
- Compilation Error (or Syntax Error): can be fixed easily.
- Runtime Error: program halts pre-maturely without producing the results - can also be fixed easily.
- Logical Error: program completes but produces incorrect results. It is easy to detect if the program always produces wrong result. It is extremely hard to fix if the program produces the correct result most of the times, but incorrect result sometimes. For example,
// Can compile and execute, but give wrong result – sometimes! if (mark > 50) { cout << "PASS" << endl; } else { cout << "FAIL" << endl; }This kind of errors is very serious if it is not caught before production. Writing good programs helps in minimizing and detecting these errors. A good testing strategy is needed to ascertain the correctness of the program. Software testing is an advanced topics which is beyond our current scope.
Debugging Programs
Here are the common debugging techniques:
- Stare at the screen! Unfortunately, errors usually won't pop-up even if you stare at it extremely hard.
- Study the error messages! Do not close the console when error occurs and pretending that everything is fine. This helps most of the times.
- Insert print statements at appropriate locations to display the intermediate results. It works for simple toy program, but it is neither effective nor efficient for complex program.
- Use a graphic debugger. This is the most effective means. Trace program execution step-by-step and watch the value of variables and outputs.
- Advanced tools such as profiler (needed for checking memory leak and function usage).
- Proper program testing to wipe out the logical errors.
Testing Your Program for Correctness
How to ensure that your program always produces correct result, 100% of the times? It is impossible to try out all the possible outcomes, even for a simple program. Program testing usually involves a set of representative test cases, which are designed to catch the major classes of errors. Program testing is beyond the scope of this writing.
Strings
C++ supports two types of strings:
- the original C-style string: A string is a
chararray, terminated with aNULLcharacter'\0'(Hex0). It is also called Character-String or C-style string. C-string will be discussed later. - the new
stringclass introduced in C++98.
The "high-level" string class is recommended, because it is much easier to use and understood. However, many legacy programs used C-strings; many programmers also use "low-level" C-strings for full control and efficiency; furthermore, in some situation such as command-line arguments, only C-strings are supported. Hence, you may have to understand both sets of strings. However, avoid C-string unless it is absolutely necessary.
We shall describe string class here, and C-string later.
String Declaration and Initialization
To use the string class, include the <string> header and "using namespace std".
You can declare and (a) initialize a string with a string literal, (b) initialize to an empty string, or (c) initialize with another string object. For example,
#include <string>
using namespace std;
string str1("Hello"); // Initialize with a string literal (Implicit initialization)
string str2 = "world"; // Initialize with a string literal (Explicit initialization via assignment operator)
string str3; // Initialize to an empty string
string str4(str1); // Initialize by copying from an existing string object
String Input/Output
For example,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
/* Testing string class input and output (TestStringIO.cpp) */ #include <iostream> #include <string> // Need this header to use string class #include <limits> using namespace std; // Also needed for <string> int main() { string message("Hello"); cout << message << endl; // Input a word (delimited by space) into a string cout << "Enter a message (no space): "; cin >> message; cout << message << endl; cin.ignore(numeric_limits<streamsize>::max(), '\n'); // flush cin up to newline (need <limits> header) // Input a line into a string cout << "Enter a message (with spaces): "; getline(cin, message); // Read input from cin into message cout << message << endl; return 0; } |
NOTES:
- We need to "
#include <string>" to use thestringclass, and "using namespace std" asstringis defined understdnamespace. - "
cin >> aStr" reads a word (delimited by space) fromcin(keyboard), and assigns tostringvariableaStr. getline(cin, aStr)reads the entire line (up to'\n') fromcin, and assigns toaStr. The'\n'character is discarded.- To flush
cin, you could useignore(numeric_limits<streamsize>::max(), '\n')function to discard all the characters up to'\n'.numeric_limitsis in the<limits>header.
String Operations
- Checking the length of a string:
int length(); int size(); both of them return the length of the string
#include <string> string str("Hello, world"); cout << str.length() << endl; // 12 cout << str.size() << endl; // 12 - Check for empty string:
bool empty(); Check if the string is empty.
string str1("Hello, world"); string str2; // Empty string cout << str1.empty() << endl; // 0 (false) cout << str2.empty() << endl; // 1 (true) - Copying from another string: Simply use the assignment (
=) operator.string str1("Hello, world"), str2; str2 = str1; cout << str2 << endl; // Hello, world - Concatenated with another string: Use the plus (+) operator, or compound plus (
+=) operator.string str1("Hello,"); string str2(" world"); cout << str1 + str2 << endl; // "Hello, world" cout << str1 << endl; // "Hello," cout << str2 << endl; // " world" str1 += str2; cout << str1 << endl; // "Hello, world" cout << str2 << endl; // " world" string str3 = str1 + str2; cout << str3 << endl; // "Hello, world world" str3 += "again"; cout << str3 << endl; // "Hello, world worldagain" - Read/Write individual character of a string:
char& at(int index); Return the char at index, index begin at 0. Perform index bound check. [] indexing (subscript) operator, no index bound check
string str("Hello, world"); cout << str.at(0) << endl; // 'H' cout << str[1] << endl; // 'e' cout << str.at(str.length() - 1) << endl; // 'd' str.at(1) = 'a'; // Write to index 1 cout << str << endl; // "Hallo, world" str[0] = 'h'; cout << str << endl; // "hallo, world" - Extracting sub-string:
string substr(int beginIndex, int size); Return the sub-string starting at beginIndex, of size
string str("Hello, world"); cout << str.substr(2, 6) << endl; // "llo, w" - Comparing with another string:
int compare(string another); Compare the content of this string with the given another. Return 0 if equals; a negative value if this string is less than another; positive value otherwise. == and != Operators Compare the contents of two strings
string str1("Hello"), str2("Hallo"), str3("hello"), str4("Hello"); cout << str1.compare(str2) << endl; // 1 'e' > 'a' cout << str1.compare(str3) << endl; // -1 'h' < 'H' cout << str1.compare(str4) << endl; // 0 // You can also use the operator == or != if (str1 == str2) cout << "Same" << endl; if (str3 != str4) cout << "Different" << endl; cout << boolalpha; // print bool as true/false cout << (str1 != str2) << endl; cout << (str1 == str4) << endl; - Search/Replacing characters: You can use the functions available in the
<algorithm>such asreplace(). For example,#include <algorithm> ...... string str("Hello, world"); replace(str.begin(), str.end(), 'l', '_'); cout << str << endl; // "He__o, wor_d" - Many others.
Example 1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
/* Example on C++ string function (TestStringOp.cpp) */ #include <iostream> #include <string> // use string class using namespace std; int main() { string msg = "hello, world!"; cout << msg << endl; cout << msg.length() << endl; // length of string cout << msg.at(1) << endl; // char at index 1 cout << msg[1] << endl; // same as above cout << msg.empty() << endl; // test for empty string cout << msg.substr(3, 3) << endl; // sub-string begins at // pos 3 of size 3 cout << msg.replace(3, 3, "why") << endl; // replace sub-string cout << msg.append("end") << endl; // append behind cout << msg + "end" << endl; // same as above cout << msg.insert(3, "insert") << endl; // insert after pos 3 string msg1; msg1 = msg; // copy cout << msg1 << endl; cout << "Enter a line: "; getline(cin, msg); // read a line of input cout << msg << endl; } |
Example 2:
[TODO]
Exercises
[TODO]
Formatting Input/Output using IO Manipulators (Header <iomanip>)
The <iomanip> header provides so-called I/O manipulators for formatting input and output:
setw(int field-width): set the field width for the next IO operation.setw()is non-sticky and must be issued prior to each IO operation. The field width is reset to the default after each operation (with just enough width to accommodate the field).
setfill(char fill-char): set the filled character for padding to the field width.left|right|internal: set the alignmentfixed/scientific(for floating-point numbers): use fixed-point notation (e.g, 12.34) or scientific notation (e.g., 1.23e+006).setprecision(int numDecimalDigits)(for floating-point numbers): specify the number of digits after the decimal point.boolalpha/noboolalpha(forbool): displayboolvalues as alphabetic string (true/false) or 1/0.
Output Formatting
Example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
/* Test Formatting Output (TestFormattedOutput.cpp) */ #include <iostream> #include <iomanip> // Needed to do formatted I/O using namespace std; int main() { // Floating point numbers double pi = 3.14159265; cout << fixed << setprecision(4); // fixed format with 4 decimal places cout << pi << endl; cout << "|" << setw(8) << pi << "|" << setw(10) << pi << "|" << endl; // setw() is not sticky, only apply to the next operation. cout << setfill('-'); cout << "|" << setw(8) << pi << "|" << setw(10) << pi << "|" << endl; cout << scientific; // in scientific format with exponent cout << pi << endl; // booleans bool done = false; cout << done << endl; // print 0 (for false) or 1 (for true) cout << boolalpha; // print true or false cout << done << endl; return 0; } |
Input Formatting
Example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
/* Test Formatting Input (TestFormattedInput.cpp) */ #include <iostream> #include <iomanip> #include <string> using namespace std; int main() { string areaCode, phoneCode; string inStr; cout << "Enter your phone number in this format (xxx)xxx-xxxx : "; cin.ignore(); // skip '(' cin >> setw(3) >> areaCode; cin.ignore(); // skip ')' cin >> setw(3) >> phoneCode; cin.ignore(); // skip '-' cin >> setw(4) >> inStr; phoneCode += inStr; cout << "Phone number is (" << areaCode << ")" << phoneCode.substr(0, 3) << "-" << phoneCode.substr(3, 4) << endl; return 0; } |
Exercises
[TODO]
Arrays
Array Declaration and Usage
Suppose that you want to find the average of the marks for a class of 30 students, you certainly do not want to create 30 variables: mark1, mark2, ..., mark30. Instead, You could use a single variable, called an array, with 30 elements.
An array is a list of elements of the same type, identified by a pair of square brackets [ ]. To use an array, you need to declare the array with 3 things: a name, a type and a dimension (or size, or length). The syntax is:
type arrayName[arraylength]; // arraylength can be a literal or a variable
I recommend using a plural name for array, e.g., marks, rows, numbers. For example,
int marks[5]; // Declare an int array called marks with 5 elements double numbers[10]; // Declare an double array of 10 elements const int SIZE = 9; float temps[SIZE]; // Use const int as array length // Some compilers support an variable as array length, e.g., int size; cout << "Enter the length of the array: "; cin >> size; float values[size];
Take note that, in C++, the value of the elements are undefined after declaration.
You can also initialize the array during declaration with a comma-separated list of values, as follows:
// Declare and initialize an int array of 3 elements int numbers[3] = {11, 33, 44}; // If length is omitted, the compiler counts the elements int numbers[] = {11, 33, 44}; // Number of elements in the initialization shall be equal to or less than length int numbers[5] = {11, 33, 44}; // Remaining elements are zero. Confusing! Don't do this int numbers[2] = {11, 33, 44}; // ERROR: too many initializers // Use {0} or {} to initialize all elements to 0 int numbers[5] = {0}; // First element to 0, the rest also to zero int numbers[5] = {}; // All element to 0 too
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
/* Test local array initialization (TestArrayInit.cpp) */ #include <iostream> using namespace std; int main() { int const SIZE = 5; int a1[SIZE]; // Uninitialized for (int i = 0; i < SIZE; ++i) cout << a1[i] << " "; cout << endl; // ? ? ? ? ? int a2[SIZE] = {21, 22, 23, 24, 25}; // All elements initialized for (int i = 0; i < SIZE; ++i) cout << a2[i] << " "; cout << endl; // 21 22 23 24 25 int a3[] = {31, 32, 33, 34, 35}; // Size deduced from init values int a3Size = sizeof(a3)/sizeof(int); cout << "Size is " << a3Size << endl; // 5 for (int i = 0; i < a3Size; ++i) cout << a3[i] << " "; cout << endl; // 31 32 33 34 35 int a4[SIZE] = {41, 42}; // Leading elements initialized, the rests to 0 for (int i = 0; i < SIZE; ++i) cout << a4[i] << " "; cout << endl; // 41 42 0 0 0 int a5[SIZE] = {0}; // First elements to 0, the rests to 0 too for (int i = 0; i < SIZE; ++i) cout << a5[i] << " "; cout << endl; // 0 0 0 0 0 int a6[SIZE] = {}; // All elements to 0 too for (int i = 0; i < SIZE; ++i) cout << a6[i] << " "; cout << endl; // 0 0 0 0 0 } |
You can refer to an element of an array via an index (or subscript) enclosed within the square bracket [ ]. C++'s array index begins with zero. For example, suppose that marks is an int array of 5 elements, then the 5 elements are: marks[0], marks[1], marks[2], marks[3], and marks[4].
// Declare & allocate a 5-element int array int marks[5]; // Assign values to the elements marks[0] = 95; marks[1] = 85; marks[2] = 77; marks[3] = 69; marks[4] = 66; cout << marks[0] << endl; cout << marks[3] + marks[4] << endl;
To create an array, you need to known the length (or size) of the array in advance, and allocate accordingly. Once an array is created, its length is fixed and cannot be changed. At times, it is hard to ascertain the length of an array (e.g., how many students in a class?). Nonetheless, you need to estimate the length and allocate an upper bound. This is probably the major drawback of using an array. C++ has a vector template class (and C++11 added an array template class), which supports dynamic resizable array.
You can find the array length using expression sizeof(arrayName)/sizeof(arrayName[0]), where sizeof(arrayName) returns the total bytes of the array and sizeof(arrayName[0]) returns the bytes of first element.
C/C++ does not perform array index-bound check. In other words, if the index is beyond the array's bounds, it does not issue a warning/error. For example,
const int size = 5; int numbers[size]; // array index from 0 to 4 // Index out of bound! // Can compiled and run, but could pose very serious side effect! numbers[88] = 999; cout << numbers[77] << endl;
This is another pitfall of C/C++. Checking the index bound consumes computation power and depicts the performance. However, it is better to be safe than fast. Newer programming languages such as Java/C# performs array index bound check.
Array and Loop
Arrays works hand-in-hand with loops. You can process all the elements of an array via a loop, for example,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
/*
* Find the mean and standard deviation of numbers kept in an array (MeanStdArray.cpp).
*/
#include <iostream>
#include <iomanip>
#include <cmath>
#define SIZE 7
using namespace std;
int main() {
int marks[] = {74, 43, 58, 60, 90, 64, 70};
int sum = 0;
int sumSq = 0;
double mean, stdDev;
for (int i = 0; i < SIZE; ++i) {
sum += marks[i];
sumSq += marks[i]*marks[i];
}
mean = (double)sum/SIZE;
cout << fixed << "Mean is " << setprecision(2) << mean << endl;
stdDev = sqrt((double)sumSq/SIZE - mean*mean);
cout << fixed << "Std dev is " << setprecision(2) << stdDev << endl;
return 0;
}
|
Exercises
[TODO]
Range-based for loop (C++11)
C++11 introduces a range-based for loop (or for-each loop) to iterate thru an array, as illustrated in the following example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
/* Testing For-each loop (TestForEach.cpp) */ #include <iostream> using namespace std; int main() { int numbers[] = {11, 22, 33, 44, 55}; // For each member called number of array numbers - read only for (int number : numbers) { cout << number << endl; } // To modify members, need to use reference (&) for (int &number : numbers) { number = 99; } for (int number : numbers) { cout << number << endl; } return 0; } |
To compile the program under GNU GCC (g++), you may need to specify option -std=c++0x or -std=c++11:
g++ -std=c++0x -o TestForEach.exe TestForEach.cpp
// or
g++ -std=c++11 -o TestForEach.exe TestForEach.cpp
Multi-Dimensional Array
For example,
int[2][3] = { {11, 22, 33}, {44, 55, 66} };
For 2D array (table), the first index is the row number, second index is the column number. The elements are stored in a so-called row-major manner, where the column index runs out first.
Example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
/* Test Multi-dimensional Array (Test2DArray.cpp) */ #include <iostream> using namespace std; void printArray(const int[][3], int); int main() { int myArray[][3] = {{8, 2, 4}, {7, 5, 2}}; // 2x3 initialized // Only the first index can be omitted and implied printArray(myArray, 2); return 0; } // Print the contents of rows-by-3 array (columns is fixed) void printArray(const int array[][3], int rows) { for (int i = 0; i < rows; ++i) { for (int j = 0; j < 3; ++j) { cout << array[i][j] << " "; } cout << endl; } } |
Array of Characters - C-String
In C, a string is a char array terminated by a NULL character '\0' (ASCII code of Hex 0). C++ provides a new string class under header <string>. The original string in C is known as C-String (or C-style String or Character String). You could allocate a C-string via:
char message[256]; // Declare a char array // Can hold a C-String of up to 255 characters terminated by '\0' char str1[] = "Hello"; // Declare and initialize with a "string literal". // The length of array is number of characters + 1 (for '\0'). char str1char[] = {'H', 'e', 'l', 'l', 'o', '\0'}; // Same as above char str2[256] = "Hello"; // Length of array is 256, keeping a smaller string.
For novices, avoid C-string. Use C++ string (in header <string>) discussed earlier.
Example
You can use cin and cout to handle C-strings.
cin <<reads a string delimited by whitespace;cin.getline(var, size)reads a string of into var till newline of length up tosize-1, discarding the newline (replaced by'\0'). Thesizetypically corresponds to the length of the C-string array.cin.get(var, size)reads a string till newline, but leaves the newline in the input buffer.cin.get(), without argument, reads the next character.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
/* Test C-string (TestCString.cpp) */ #include <iostream> using namespace std; int main() { char msg[256]; // Hold a string of up to 255 characters (terminated by '\0') cout << "Enter a message (with space)" << endl; cin.getline(msg, 256); // Read up to 255 characters into msg cout << msg << endl; // Access via null-terminated character array for (int i = 0; msg[i] != '\0'; ++i) { cout << msg[i]; } cout << endl; cout << "Enter a word (without space)" << endl; cin >> msg; cout << msg << endl; // Access via null-terminated character array for (int i = 0; msg[i] != '\0'; ++i) { cout << msg[i]; } cout << endl; return 0; } |
Exercises
[TODO]
Functions
Why Functions?
At times, a certain portion of codes has to be used many times. Instead of re-writing the codes many times, it is better to put them into a "subroutine", and "call" this "subroutine" many time - for ease of maintenance and understanding. Subroutine is called method (in Java) or function (in C/C++).
The benefits of using functions are:
- Divide and conquer: construct the program from simple, small pieces or components. Modularize the program into self-contained tasks.
- Avoid repeating codes: It is easy to copy and paste, but hard to maintain and synchronize all the copies.
- Software Reuse: you can reuse the functions in other programs, by packaging them into library codes.
Two parties are involved in using a function: a caller who calls the function, and the function called. The caller passes argument(s) to the function. The function receives these argument(s), performs the programmed operations within the function's body, and returns a piece of result back to the caller.
Using Functions
Get Started with an Example
Suppose that we need to evaluate the area of a circle many times, it is better to write a function called getArea(), and re-use it when needed.
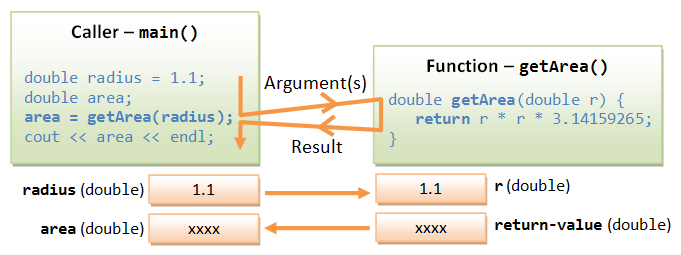
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
/* Test Function (TestFunction.cpp) */ #include <iostream> using namespace std; const int PI = 3.14159265; // Function Prototype (Function Declaration) double getArea(double radius); int main() { double radius1 = 1.1, area1, area2; // call function getArea() area1 = getArea(radius1); cout << "area 1 is " << area1 << endl; // call function getArea() area2 = getArea(2.2); cout << "area 2 is " << area2 << endl; // call function getArea() cout << "area 3 is " << getArea(3.3) << endl; } // Function Definition // Return the area of a circle given its radius double getArea(double radius) { return radius * radius * PI; } |
area 1 is 3.63 area 2 is 14.52 area 3 is 32.67
In the above example, a reusable function called getArea() is defined, which receives a parameter (in double) from the caller, performs the calculation, and return a piece of result (in double) to the caller. In the main(), we invoke getArea() functions thrice, each time with a different parameter.
In C++, you need to declare a function prototype (before the function is used), and provide a function definition, with a body containing the programmed operations.
Function Definition
The syntax for function definition is as follows:
returnValueType functionName ( parameterList ) {
functionBody ;
}
- The parameterList consists of comma-separated parameter-type and parameter-name, i.e.,
param-1-type param-1-name, param-2-type param-2-name,... - The returnValueType specifies the type of the return value, such as
intordouble. An special return type calledvoidcan be used to denote that the function returns no value. In C++, a function is allowed to return one value or no value (void). It cannot return multiple values. [C++ does not allow you to return an array!]
The "return" Statement
Inside the function's body, you could use a return statement to return a value (of the returnValueType declared in the function's header) and pass the control back to the caller. The syntax is:
return expression; // Evaluated to a value of returnValueType declared in function's signature return; // For function with return type of void
Take note that invoking a function (by the caller) transfers the control to the function. The return statement in the function transfers the control back to the caller.
Function Naming Convention
A function's name shall be a verb or verb phrase (action), comprising one or more words. The first word is in lowercase, while the rest are initial-capitalized (known as camel-case). For example, getArea(), setRadius(), moveDown(), isPrime(), etc.
Function Prototype
In C++, a function must be declared before it can be called. It can be achieved by either placing the function definition before it is being used, or declare a so-called function prototype.
A function prototype tells the compiler the function's interface, i.e., the return-type, function name, and the parameter type list (the number and type of parameters). The function can now be defined anywhere in the file. For example,
// Function prototype - placed before the function is used. double getArea(double); // without the parameter name int max(int, int);
You could optionally include the parameter names in the function prototype. The names will be ignored by the compiler, but serve as documentation. For example,
// Function Prototype double getArea(double radius); // parameter names are ignored, but serve as documentation int max(int number1, int number2);
Function prototypes are usually grouped together and placed in a so-called header file. The header file can be included in many programs. We will discuss header file later.
Another Example
We have a function called max(int, int), which takes two int and return their maximum. We invoke the max() function from the main().
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
/* Testing max function (TestMaxFunction.cpp) */ #include <iostream> using namespace std; int maximum(int, int); // Function prototype (declaration) int main() { cout << maximum(5, 8) << endl; // Call maximum() with literals int a = 6, b = 9, c; c = maximum(a, b); // Call maximum() with variables cout << c << endl; cout << maximum(c, 99) << endl; // Call maximum() } // Function definition // A function that returns the maximum of two given int int maximum(int num1, int num2) { return (num1 > num2) ? num1 : num2; } |
The "void" Return Type
Suppose that you need a function to perform certain actions (e.g., printing) without a need to return a value to the caller, you can declare its return-value type as void. In the function's body, you could use a "return;" statement without a return value to return control to the caller. In this case, the return statement is optional. If there is no return statement, the entire body will be executed, and control returns to the caller at the end of the body.
Actual Parameters vs. Formal Parameters
Recall that a function receives arguments from its caller, performs the actions defined in the function's body, and return a value (or nothing) to the caller.
In the above example, the variable (double radius) declared in the signature of getArea(double radius) is known as formal parameter. Its scope is within the function's body. When the function is invoked by a caller, the caller must supply so-called actual parameters (or arguments), whose value is then used for the actual computation. For example, when the function is invoked via "area1 = getArea(radius1)", radius1 is the actual parameter, with a value of 1.1.
Scope of Function's Local Variables and Parameters
All variables, including function's parameters, declared inside a function are available only to the function. They are created when the function is called, and freed (destroyed) after the function returns. They are called local variables because they are local to the function and not available outside the function. They are also called automatic variables, because they are created and destroyed automatically - no programmer's explicit action needed to allocate and deallocate them.
Boolean Functions
A boolean function returns a bool value (of either true or false) to the caller.
Suppose that we wish to write a function called isOdd() to check if a given number is odd.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
/* * Test Boolean function (BooleanfunctionTest.cpp). */ #include <iostream> using namespace std; // Function Prototype bool isOdd(int); int main() { cout << boolalpha; // print bool as true or false cout << isOdd(5) << endl; // true cout << isOdd(6) << endl; // false cout << isOdd(-5) << endl; // false } bool isOdd(int number) { if (number % 2 == 1) { return true; } else { return false; } } |
This seemingly correct codes produces false for -5, because -5%2 is -1 instead of 1. You may rewrite the condition:
bool isOdd(int number) {
if (number % 2 == 0) {
return false;
} else {
return true;
}
}
The above code produces the correct answer, but is poor. For boolean function, you should simply return the resultant bool value of the comparison, instead of using a conditional statement, as follow:
bool isEven(int number) {
return (number % 2 == 0);
}
bool isOdd(int number) {
return !(number % 2 == 0); // OR return !isEven(number);
}
int main() {
int number = -9;
if (isEven(number)) { // Don't write (isEven(number) == true)
cout << "Even" << endl;
}
}
Default Arguments
C++ introduces so-called default arguments for functions. These default values would be used if the caller omits the corresponding actual argument in calling the function. Default arguments are specified in the function prototype, and cannot be repeated in the function definition. The default arguments are resolved based on their positions. Hence, they can only be used to substitute the trailing arguments to avoid ambiguity. For example,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
/* Test Function default arguments (functionDefaultArgument.cpp) */ #include <iostream> using namespace std; // Function prototype - Specify the default arguments here int fun1(int = 1, int = 2, int = 3); int fun2(int, int, int = 3); int main() { cout << fun1(4, 5, 6) << endl; // No default cout << fun1(4, 5) << endl; // 4, 5, 3(default) cout << fun1(4) << endl; // 4, 2(default), 3(default) cout << fun1() << endl; // 1(default), 2(default), 3(default) cout << fun2(4, 5, 6) << endl; // No default cout << fun2(4, 5) << endl; // 4, 5, 3(default) // cout << fun2(4) << endl; // error: too few arguments to function 'int fun2(int, int, int)' } int fun1(int n1, int n2, int n3) { // cannot repeat default arguments in function definition return n1 + n2 + n3; } int fun2(int n1, int n2, int n3) { return n1 + n2 + n3; } |
You should specify the default arguments in the function prototype (declaration). They can only be defined once (one-definition rule), and cannot be repeated in the function definition.
Default argument is not absolutely necessary. The codes could be hard to maintain.
Function Overloading
C++ introduces function overloading (or function polymorphism, which means many forms), which allows you to have multiple versions of the same function name, differentiated by the parameter list (number, type or order of parameters). The version matches the caller's argument list will be selected for execution. For example,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
/* Test Function Overloading (FunctionOverloading.cpp) */ #include <iostream> using namespace std; void fun(int, int, int); // Version 1 void fun(double, int); // Version 2 void fun(int, double); // Version 3 int main() { fun(1, 2, 3); // version 1 fun(1.0, 2); // version 2 fun(1, 2.0); // version 3 fun(1.1, 2, 3); // version 1 - double 1.1 casted to int 1 (without warning) // fun(1, 2, 3, 4); // error: no matching function for call to 'fun(int, int, int, int)' // fun(1, 2); // error: call of overloaded 'fun(int, int)' is ambiguous // note: candidates are: // void fun(double, int) // void fun(int, double) // fun(1.0, 2.0); // error: call of overloaded 'fun(double, double)' is ambiguous } void fun(int n1, int n2, int n3) { // version 1 cout << "version 1" << endl; } void fun(double n1, int n2) { // version 2 cout << "version 2" << endl; } void fun(int n1, double n2) { // version 3 cout << "version 3" << endl; } |
Overloaded functions cannot be differentiated by the return-type (compilation error).
*Name Mangling
To differentiate between different versions of an overloaded function, many compilers (such as GNU GCC) adopt a name mangling or name decoration scheme for naming functions.
// Compile source into object code FunctionOverloading.o > g++ -c FunctionOverloading.cpp // List the symbol table > nm FunctionOverloading.o ...... 000000b5 T __Z3fundi 000000ed T __Z3funid 00000089 T __Z3funiii ......
Each of the function is identified via a prefix __Z, followed by an integer containing the number of characters of the function name (3 in this case for "fun"), followed by the parameter type list (where i for int and d for double). For example, di means a double followed by an int; id for an int followed by a double; iii for 3 ints.
You can choose to use the C's naming protocol by appending the keyword extern "C" to the function prototype. C does not support function overloading. Thus, it does not need name mangling. It simply append an underscore in front of the function name. For example,
extern "C" void fun(int, int, int, int); // Compiled as _fun
Functions and Arrays
You can also pass arrays into function. However, you also need to pass the size of the array into the function. This is because there is no way to tell the size of the array from the array argument inside the called function.
For example,
Example: Computing the Sum of an Array and Print Array's Contents
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
/* Function to compute the sum of an array (SumArray.cpp) */ #include <iostream> using namespace std; // Function prototype int sum(int array[], int size); // Need to pass the array size too void print(int array[], int size); // Test Driver int main() { int a1[] = {8, 4, 5, 3, 2}; print(a1, 5); // {8,4,5,3,2} cout << "sum is " << sum(a1, 5) << endl; // sum is 22 } // Function definition // Return the sum of the given array int sum(int array[], int size) { int sum = 0; for (int i = 0; i < size; ++i) { sum += array[i]; } return sum; } // Print the contents of the given array void print(int array[], int size) { cout << "{"; for (int i = 0; i < size; ++i) { cout << array[i]; if (i < size - 1) { cout << ","; } } cout << "}" << endl; } |
Pass-by-Value vs. Pass-by-Reference
There are two ways that a parameter can be passed into a function: pass by value vs. pass by reference.
Pass-by-Value
In pass-by-value, a "copy" of argument is created and passed into the function. The invoked function works on the "clone", and cannot modify the original copy. In C/C++, fundamental types (such as int and double) are passed by value. That is, you cannot modify caller's value inside the function - there is no side effect.
Example (Fundamental Types are Passed by Value)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
/* Fundamental types are passed by value into Function (TestPassByValue.cpp) */ #include <iostream> using namespace std; // Function prototypes int inc(int number); // Test Driver int main() { int n = 8; cout << "Before calling function, n is " << n << endl; // 8 int result = inc(n); cout << "After calling function, n is " << n << endl; // 8 cout << "result is " << result << endl; // 9 } // Function definitions // Return number+1 int inc(int number) { ++number; // Modify parameter, no effect to caller return number; } |
Pass-by-Reference
On the other hand, in pass-by-reference, a reference of the caller's variable is passed into the function. In other words, the invoked function works on the same data. If the invoked function modifies the parameter, the same caller's copy will be modified as well.
In C/C++, arrays are passed by reference. That is, you can modify the contents of the caller's array inside the invoked function - there could be side effect in passing arrays into function.
C/C++ does not allow functions to return an array. Hence, if you wish to write a function that modifies the contents of an array (e.g., sorting the elements of an array), you need to rely on pass-by-reference to work on the same copy inside and outside the function. Recall that in pass-by-value, the invoked function works on a clone copy and has no way to modify the original copy.
Example (Array is passed by Reference): Increment Each Element of an Array
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
/* Function to increment each element of an array (IncrementArray.cpp) */ #include <iostream> using namespace std; // Function prototypes void inc(int array[], int size); void print(int array[], int size); // Test Driver int main() { int a1[] = {8, 4, 5, 3, 2}; // Before increment print(a1, 5); // {8,4,5,3,2} // Do increment inc(a1, 5); // Array is passed by reference (having side effect) // After increment print(a1, 5); // {9,5,6,4,3} } // Function definitions // Increment each element of the given array void inc(int array[], int size) { // array[] is not const for (int i = 0; i < size; ++i) { array[i]++; // side-effect } } // Print the contents of the given array void print(int array[], int size) { cout << "{"; for (int i = 0; i < size; ++i) { cout << array[i]; if (i < size - 1) { cout << ","; } } cout << "}" << endl; } |
Array is passed into function by reference. That is, the invoked function works on the same copy of the array as the caller. Hence, changes of array inside the function is reflected outside the function (i.e., side effect).
Why Arrays are Pass-by-Reference?
Array is designed to be passed by reference, instead of by value using a cloned copy. This is because passing huge array by value is inefficient - the huge array needs to be cloned.
const Function Parameters
Pass-by-reference risks corrupting the original data. If you do not have the intention of modifying the arrays inside the function, you could use the const keyword in the function parameter. A const function argument cannot be modified inside the function.
Use const whenever possible for passing references as it prevent you from inadvertently modifying the parameters and protects you against many programming errors.
Example: Search an Array using Linear Search
In a linear search, the search key is compared with each element of the array linearly. If there is a match, it returns the index of the array between [0, size-1]; otherwise, it returns -1 or the size of of the array (some implementations deal with only positive indexes). Linear search has complexity of O(n).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
/* Search an array for the given key using Linear Search (LinearSearch.cpp) */ #include <iostream> using namespace std; int linearSearch(const int a[], int size, int key); int main() { const int SIZE = 8; int a1[SIZE] = {8, 4, 5, 3, 2, 9, 4, 1}; cout << linearSearch(a1, SIZE, 8) << endl; // 0 cout << linearSearch(a1, SIZE, 4) << endl; // 1 cout << linearSearch(a1, SIZE, 99) << endl; // 8 (not found) } // Search the array for the given key // If found, return array index [0, size-1]; otherwise, return size int linearSearch(const int a[], int size, int key) { for (int i = 0; i < size; ++i) { if (a[i] == key) return i; } return size; } |
Program Notes:
- [TODO]
Example: Sorting an Array using Bubble Sort
Wiki "Bubble Sort" for the detailed algorithm and illustration. In brief, we pass thru the list, compare two adjacent items and swap them if they are in the wrong order. Repeat the pass until no swaps are needed. For example,
{8,4,5,3,2,9,4,1}
PASS 1 ...
{8,4,5,3,2,9,4,1} => {4,8,5,3,2,9,4,1}
{4,8,5,3,2,9,4,1} => {4,5,8,3,2,9,4,1}
{4,5,8,3,2,9,4,1} => {4,5,3,8,2,9,4,1}
{4,5,3,8,2,9,4,1} => {4,5,3,2,8,9,4,1}
{4,5,3,2,8,9,4,1} => {4,5,3,2,8,4,9,1}
{4,5,3,2,8,4,9,1} => {4,5,3,2,8,4,1,9}
PASS 2 ...
{4,5,3,2,8,4,1,9} => {4,3,5,2,8,4,1,9}
{4,3,5,2,8,4,1,9} => {4,3,2,5,8,4,1,9}
{4,3,2,5,8,4,1,9} => {4,3,2,5,4,8,1,9}
{4,3,2,5,4,8,1,9} => {4,3,2,5,4,1,8,9}
PASS 3 ...
{4,3,2,5,4,1,8,9} => {3,4,2,5,4,1,8,9}
{3,4,2,5,4,1,8,9} => {3,2,4,5,4,1,8,9}
{3,2,4,5,4,1,8,9} => {3,2,4,4,5,1,8,9}
{3,2,4,4,5,1,8,9} => {3,2,4,4,1,5,8,9}
PASS 4 ...
{3,2,4,4,1,5,8,9} => {2,3,4,4,1,5,8,9}
{2,3,4,4,1,5,8,9} => {2,3,4,1,4,5,8,9}
PASS 5 ...
{2,3,4,1,4,5,8,9} => {2,3,1,4,4,5,8,9}
PASS 6 ...
{2,3,1,4,4,5,8,9} => {2,1,3,4,4,5,8,9}
PASS 7 ...
{2,1,3,4,4,5,8,9} => {1,2,3,4,4,5,8,9}
PASS 8 ...
{1,2,3,4,4,5,8,9}
Bubble sort is not efficient, with complexity of O(n2).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
/* Sorting an array using Bubble Sort (BubbleSort.cpp) */ #include <iostream> using namespace std; void bubbleSort(int a[], int size); void print(const int a[], int size); int main() { const int SIZE = 8; int a[] = {8, 4, 5, 3, 2, 9, 4, 1}; print(a, SIZE); cout << endl; bubbleSort(a, SIZE); print(a, SIZE); cout << endl; } // Sort the given array of size void bubbleSort(int a[], int size) { bool done = false; // terminate if no more swap thru a pass int pass = 0; // pass number, for tracing int temp; // use for swapping while (!done) { cout << "PASS " << ++pass << " ..." << endl; // for tracing done = true; // Pass thru the list, compare adjacent items and swap // them if they are in wrong order for (int i = 0; i < size - 1; ++i) { if (a[i] > a[i+1]) { print(a, size); // for tracing temp = a[i]; a[i] = a[i+1]; a[i+1] = temp; done = false; // swap detected, one more pass cout << "=> "; // for tracing print(a, size); cout << endl; } } } } // Print the contents of the given array of size void print(const int a[], int size) { cout << "{"; for (int i = 0; i < size; ++i) { cout << a[i]; if (i < size - 1) cout << ","; } cout << "} "; } |
Program Notes:
- [TODO]
Example: Sorting an Array using Insertion Sort
Wiki "Insertion Sort" for the algorithm and illustration. In brief, pass thru the list. For each element, compare with all previous elements and insert it at the correct position by shifting the other elements. For example,
{8,4,5,3,2,9,4,1}
{8} {4,5,3,2,9,4,1}
{4,8} {5,3,2,9,4,1}
{4,5,8} {3,2,9,4,1}
{3,4,5,8} {2,9,4,1}
{2,3,4,5,8} {9,4,1}
{2,3,4,5,8,9} {4,1}
{2,3,4,4,5,8,9} {1}
{1,2,3,4,4,5,8,9}
Insertion sort is also not efficient, with complexity of O(n2).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
/* Sorting an array using Insertion Sort (InsertionSort.cpp) */ #include <iostream> using namespace std; void insertionSort(int a[], int size); void print(const int a[], int iMin, int iMax); int main() { const int SIZE = 8; int a[SIZE] = {8, 4, 5, 3, 2, 9, 4, 1}; print(a, 0, SIZE - 1); cout << endl; insertionSort(a, SIZE); print(a, 0, SIZE - 1); cout << endl; } // Sort the given array of size using insertion sort void insertionSort(int a[], int size) { int temp; // for shifting elements for (int i = 1; i < size; ++i) { // for tracing print(a, 0, i - 1); // already sorted print(a, i, size - 1); // to be sorted cout << endl; // For element at i, insert into proper position in [0, i-1] // which is already sorted. // Shift down the other elements for (int prev = 0; prev < i; ++prev) { if (a[i] < a[prev]) { // insert a[i] at prev, shift the elements down temp = a[i]; for (int shift = i; shift > prev; --shift) { a[shift] = a[shift-1]; } a[prev] = temp; break; } } } } // Print the contents of the array in [iMin, iMax] void print(const int a[], int iMin, int iMax) { cout << "{"; for (int i = iMin; i <= iMax; ++i) { cout << a[i]; if (i < iMax) cout << ","; } cout << "} "; } |
Program Notes:
- [TODO]
Example: Sorting an Array using Selection Sort
Wiki "Selection Sort" for the algorithm and illustration. In brief, Pass thru the list. Select the smallest element and swap with the head of the list. For example,
{8,4,5,3,2,9,4,1}
{} {8,4,5,3,2,9,4,1} => {} {1,4,5,3,2,9,4,8}
{1} {4,5,3,2,9,4,8} => {1} {2,5,3,4,9,4,8}
{1,2} {5,3,4,9,4,8} => {1,2} {3,5,4,9,4,8}
{1,2,3} {5,4,9,4,8} => {1,2,3} {4,5,9,4,8}
{1,2,3,4} {5,9,4,8} => {1,2,3,4} {4,9,5,8}
{1,2,3,4,4} {9,5,8} => {1,2,3,4,4} {5,9,8}
{1,2,3,4,4,5} {9,8} => {1,2,3,4,4,5} {8,9}
{1,2,3,4,4,5,8,9}
Selection sort is also not efficient, with complexity of O(n2).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
/* Sorting an array using Selection Sort (SelectionSort.cpp) */ #include <iostream> using namespace std; void selectionSort(int a[], int size); void print(const int a[], int iMin, int iMax); int main() { const int SIZE = 8; int a[SIZE] = {8, 4, 5, 3, 2, 9, 4, 1}; print(a, 0, SIZE - 1); cout << endl; selectionSort(a, SIZE); print(a, 0, SIZE - 1); cout << endl; } // Sort the given array of size using selection sort void selectionSort(int a[], int size) { int temp; // for swapping for (int i = 0; i < size - 1; ++i) { // for tracing print(a, 0, i - 1); print(a, i, size - 1); // [0, i-1] already sort // Search for the smallest element in [i, size-1] // and swap with a[i] int minIndex = i; // assume fist element is the smallest for (int j = i + 1; j < size; ++j) { if (a[j] < a[minIndex]) minIndex = j; } if (minIndex != i) { // swap temp = a[i]; a[i] = a[minIndex]; a[minIndex] = temp; } // for tracing cout << "=> "; print(a, 0, i - 1); print(a, i, size - 1); cout << endl; } } // Print the contents of the array in [iMin, iMax] void print(const int a[], int iMin, int iMax) { cout << "{"; for (int i = iMin; i <= iMax; ++i) { cout << a[i]; if (i < iMax) cout << ","; } cout << "} "; } |
Program Notes:
- [TODO]
"const" Fundamental-Type Function Parameters?
You could also use const for fundamental-type function parameters (such as int, double) to prevent the parameters from being modified inside the function. However, as fundamental-type parameters are passed by value (with a cloned copy), there will never be side effect on the caller. We typically do not use the const keyword for fundamental types. In other words, const is used to indicate that there shall NOT be side-effect.
Pass-by-Reference via "Reference" Parameters
As mentioned, parameters of fundamental types (such as int, double) are passed-by-value. That is, a clone copy is used inside the function. Change to the cloned copy inside the function has no side-effect to the caller's copy.
Nonetheless, you can pass a fundamental type parameter by reference via the so-called reference parameter denoted by &. For example,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
/* Test Pass-by-reference for fundamental-type parameter via reference declaration (TestPassByReference.cpp) */ #include <iostream> using namespace std; int squareByValue (int number); // Pass-by-value void squareByReference (int & number); // Pass-by-reference int main() { int n1 = 8; cout << "Before call, value is " << n1 << endl; // 8 cout << squareByValue(n1) << endl; // no side-effect cout << "After call, value is " << n1 << endl; // 8 int n2 = 9; cout << "Before call, value is " << n2 << endl; // 9 squareByReference(n2); // side-effect cout << "After call, value is " << n2 << endl; // 81 } // Pass parameter by value - no side effect int squareByValue (int number) { return number * number; } // Pass parameter by reference by declaring as reference (&) // - with side effect to the caller void squareByReference (int & number) { number = number * number; } |
In function squareByReference(), we declare the parameter number is passed by reference by declaring its type as int & (reference of int). In this way, the caller's copy is used inside the function (instead of a cloned copy in pass-by-value). Changes inside the function has side-effect.
Pass-by-reference is NOT commonly used for fundamental types (such as int, double) - the above example is purely meant for academic illustration. But it is used extensively for compound types (such as arrays and objects) to avoid cloning huge data for better performance. We shall revisit pass-by-reference in Object-Oriented Programming (OOP) chapters.
Mathematical Functions (Header <cmath>)
C++ provides many common-used Mathematical functions in library <cmath> (ported over from C's "math.h"). The signatures of some of these functions are:
sin(x), cos(x), tan(x), asin(x), acos(x), atan(x): Take argument-type and return-type of float, double, long double. |
atan2(y, x): Return arc-tan of y/x. Better than atan(x) for handling 90 degree. |
sinh(x), cosh(x), tanh(x): hyper-trigonometric functions. |
pow(x, y), sqrt(x): power and square root. |
ceil(x), floor(x): returns the ceiling and floor integer of floating point number. |
fabs(x), fmod(x, y): floating-point absolute and modulus. |
exp(x), log(x), log10(x): exponent and logarithm functions. |
Generating Random Numbers
The cstdlib header (ported from C's stdlib.h) provides a function rand(), which generates a pseudo-random integral number between 0 and RAND_MAX (inclusive). RAND_MAX is a constant defined in cstdlib (typically the maximum value of 16-/32-bit signed integer, such as 32767). You can generate a random number between [0,n) via rand() % n.
rand() generates the same squence of pseudo-random numbers on different invocations. The cstblib also provides a srand() function to seed or initialize the random number generator. We typically seed it with the current time obtained via time(0) function (in <ctime> header), which returns the number of seconds since January 1st, 1970.
Example 1: Test rand() and srand(time(0))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
/* Test Random Number Generation (TestRand.cpp) */ #include <iostream> #include <cstdlib> // for rand(), srand() #include <ctime> // for time() using namespace std; int main() { // rand() generate a random number in [0, RAND_MAX] cout << "RAND_MAX is " << RAND_MAX << endl; // 32767 // Generate 10 pseudo-random numbers between 0 and 99 // without seeding the generator. // You will get the same sequence, every time you run this program for (int i = 0; i < 10; ++i) { cout << rand() % 100 << " "; // need <cstdlib> header } cout << endl; // Seed the random number generator with current time srand(time(0)); // need <cstdlib> and <ctime> header // Generate 10 pseudo-random numbers // You will get different sequence on different run, // because the current time is different for (int i = 0; i < 10; ++i) { cout << rand() % 100 << " "; // need <cstdlib> header } cout << endl; } |
Example 2: Test rand()'s Distribution
We shall test the rand()'s distribution by repeatedly throwing a 6-sided die and count the occurrences.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
/* Test rand() distribution by throwing a die repeatedly (TestRandomDie.cpp) */ #include <iostream> #include <iomanip> #include <cstdlib> // for rand(), srand() #include <ctime> // for time() using namespace std; const int TOTAL_COUNT = 2000000; // Close to INT_MAX const int NUM_FACES = 6; int frequencies[6] = {0}; // frequencies of 0 to 5, init to zero int main() { srand(time(0)); // seed random number generator with current time // Throw the die and count the frequencies for (int i = 0; i < TOTAL_COUNT; ++i) { ++frequencies[rand() % 6]; } // Print statistics cout << fixed << setprecision(2); for (int i = 0; i < NUM_FACES; i++) { cout << i+1 << ": " << frequencies[i] << " (" << 100.0 * frequencies[i] / TOTAL_COUNT << "%)" << endl; } } |
1: 333109 (16.66%) 2: 333113 (16.66%) 3: 333181 (16.66%) 4: 333562 (16.68%) 5: 333601 (16.68%) 6: 333434 (16.67%)
As seen from the output, rand() is fairly uniformly-distributed over [0, RAND_MAX].
Exercises
[TODO]
File Input/Output (Header <fstream>)
The <fstream> header provides ifstream (input file stream) and ofstream (output file stream) for file input and output. The steps for file input/output are:
- Create a
ifstreamfor input, orofstreamfor output. - Connect the stream to an input or output file via
open(filename). - Perform formatted output via stream insertion operator
<<, or input via stream extraction operator>>, similar tocout <<andcin >>. - Close the file and free the stream.
Example: File IO
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
/* Test File I/O (TestFileIO.cpp) Read all the integers from an input file and write the average to an output file */ #include <iostream> #include <fstream> // file stream #include <cstdlib> using namespace std; int main() { ifstream fin; // Input stream ofstream fout; // Output stream // Try opening the input file fin.open("in.txt"); if (!fin.is_open()) { cerr << "error: open input file failed" << endl; abort(); // Abnormally terminate the program (in <cstdlib>) } int sum = 0, number, count = 0; while (!(fin.eof())) { // Use >> to read fin >> number; sum += number; ++count; } double average = double(sum) / count; cout << "Count = " << count << " average = " << average << endl; fin.close(); // Try opening the output file fout.open("out.txt"); if (!fout.is_open()) { cerr << "error: open output file failed" << endl; abort(); } // Write the average to the output file using << fout << average; fout.close(); return 0; } |
Input File: in.txt
12 15 35 26 68
Output File: out.txt
31.20
Program Notes:
- Once the file is opened, you can use
>>and<<for input and output, similar tocin >>andcout <<. (Advanced note:ifstreamis a subclass ofistream, wherecinbelongs.ofstreamis a subclassof ostream, wherecoutbelongs.) - Similarly, IO manipulators, such as
fixed,setprecision()andsetw(), work on the file streams.
Exercises
[TODO]
Namespace
When you use different library modules, there is always a potential for name crashes, as different library may use the same name for different purposes. This problem can be resolved via the use of namespace in C++. A namespace is a collection for identifiers under the same naming scope. (It is known as package in UML and Java.) The entity name under a namespace is qualified by the namespace name, followed by :: (known as scope resolution operator), in the form of namespace::entityName.
To place an entity under a namespace, use keyword namespace as follow:
// create a namespace called myNamespace for the enclosed entities namespace myNameSpace { int foo; // variable int f() { ...... }; // function class Bar { ...... }; // compound type such as class and struct } // To reference the entities, use myNameSpace::foo myNameSpace::f() myNameSpace::Bar
A namespace can contain variables, functions, arrays, and compound types such as classes and structures.
Namespace Example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#include <iostream>
namespace a { // contains variables
int i1 = 8;
int i2 = 9;
}
namespace b { // contains function
int max(int n1, int n2) {
return (n1 > n2) ? n1 : n2;
}
}
int main() {
std::cout << a::i1 << std::endl; // 8
std::cout << b::max(a::i1, a::i2) << std::endl; // 9
}
|
Namespaces are opened. In other words, you can add more names into an existing namespace using additional namespace definition.
Using Namespace
For example, all the identifiers in the C++ standard libraries (such as cout, endl and string) are placed under the namespace called std. To reference an identifier under a namespace, you have three options:
- Use the fully qualified names, such as
std::cout,std::endl,std::setw()andstd::string. For example,std::cout << std::setw(6) << 1234 << std::endl;
Missing the "std::" results in "error: 'xxx' was not declared in this scope". - Use a using declaration to declare the particular identifiers. For example,
using std::cout; using std::endl; ...... cout << std::setw(6) << 1234 << endl;
You can omit the "std::" forcoutandendl, but you still have to use "std::" forsetw. - Use a using namespace directive. For example,
using namespace std; ...... cout << setw(6) << 1234 << endl;
Theusing namespacedirective effectively brings all the identifiers from the specified namespace to the global scope, as if they are available globally. You can reference them without the scope resolution operator. Take note that theusing namespacedirective may result in name crashes with identifier in the global scope. - For long namespace name, you could define a shorthand (or alias) to the namespace, as follows:
namespace shorthand = namespace-name;
You can now refer to your class asshorthand::entityName.
As mentioned, all the standard C++ library components are packaged inside a namespace called std. They include cin, cout, endl, setw(), setprecision(), and string. Hence, we always included a "using namespace std;" directive after the "#include <iostream>" and "#include <string>". You could also use the qualified name such as std::cin, std::cout, std::endl, std::string, instead of the using directive. You could also use selective using such as "using std::cin;", "using std::cout;", "using std::endl;" and "using std::string;".
Compare the following two code samples:
#include <iostream>
using namespace std; // std namespace is available to ALL
int main() { ....... }
#include <iostream>
int main() {
using namespace std; // std namespace is available to main() only
.......
}
Note: you could use the C-style header "iostream.h" which does not use namespace to replace the first two lines in the first sample.
Global Namespace
In C++, an entity (variable, function, or class) belongs to the global namespace (identified by :: with no namespace name), if it is not enclose within a namespace declaration. For example, main() can be identified as ::main().