Portrait stylization involves taking a real portrait photo as input, and converting it into a particular
style, e.g. cartoonization. However, it's very time consuming to train different style generators,
often requiring a lot of style domain training data. The proposed AgileGAN framework uses a hierarchical variational
autoencoder that learns an inverse mapping into the StyleGAN2 latent space, but which is specifically
designed to preserves the original code distribution in the mapping. This regularization allows rapid
training on a small style domain dataset to fine-tune the generator to get desired stylization
results. This makes the framework "agile", and allows many generators to be quickly
trained for different styles, e.g. cartoon, oil painting, charcoal, sculpture, etc.
Guoxian Song, Linjie Luo, Jing Liu, Wan-Chun Ma, Chunpong Lai, Chuanxia Zheng,
Tat-Jen Cham, AgileGAN: stylizing portraits by inversion-consistent transfer learning, SIGGRAPH,
Los Angeles, CA, USA, 2021
Ever had casual holiday photos turn out poor due to bad lighting? Our deep learning framework is
able to relight portrait photos to the target lighting seen in another reference photo. At the heart of
the method is an overcomplete latent representation that redundantly codes for the same lighting under
three 90° rotations. This redundancy helps the latent space self-organize better — not only is the
relighting better, but it also allows for the light to be interactively manipulated. This image-based
framework uses latent representations and neural rendering, without the need for 3D estimation or inverse
rendering.
Guoxian Song, Tat-Jen Cham, Jianfei Cai, Jianmin Zheng, Half-body portrait
relighting with overcomplete lighting representation, Computer Graphics Forum (CGF), 2021.
Unpaired image-to-image translation is conceptually problematic. Why? Because how do we decide
what is a "good" translation for the network to learn? Unlike previous work that use hand-crafted
loss functions to get good results in practice, this work proposes to use a key
assumption based on a fundamental insight — that the scene structure in two domains are
the same when the patterns of self-similarity within each scene are the same. A "good"
translation preserves this scene structure, even when the domains are very different. A learned
spatially-correlative loss is proposed that capitalizes on this principled insight.
Chuanxia Zheng, Tat-Jen Cham, Jianfei Cai, The spatially-correlative loss for
various image translation tasks, Conference on Computer Vision and Pattern Recognition (CVPR),
Nashville, TN, USA, 2021.
A deep learning framework for image completion / inpainting that is capable of synthesizing
a widely diverse range of plausible results for erased portions of an image. This is unlike previous image
completion work that generate only one solution, or with very limited variation, per masked input. The paper
provides detailed mathematical analysis as to why directly using conventional approaches (e.g. CVAE, or simple hybrids
of) do not work well.
Chuanxia Zheng, Tat-Jen Cham, Jianfei Cai, Pluralistic image completion, Conference on Computer Vision
and Pattern Recognition (CVPR), Long Beach, CA, USA, 2019.
T2Net: Synthetic-to-Realistic Translation for Solving Single-Image Depth Estimation Tasks
(ECCV 2018)
A deep learning framework for estimating 3D depth maps from single images,
that utilizes synthetic models in training, without the need to depend on real
3D depth maps that are hard to acquire, and typically very incomplete and noisy.
Part of the process involves learning to intensify the realism of
OpenGL-rendered images.
Chuanxia Zheng, Tat-Jen Cham, Jianfei Cai, T2Net: synthetic-to-realistic
translation for solving single-image depth estimation tasks, European Conference on Computer
Vision (ECCV), Munich, Germany, 2018.
Real-time 3D Face-Eye Performance Capture of a Person Wearing VR Headset
(ACM Multimedia 2018)
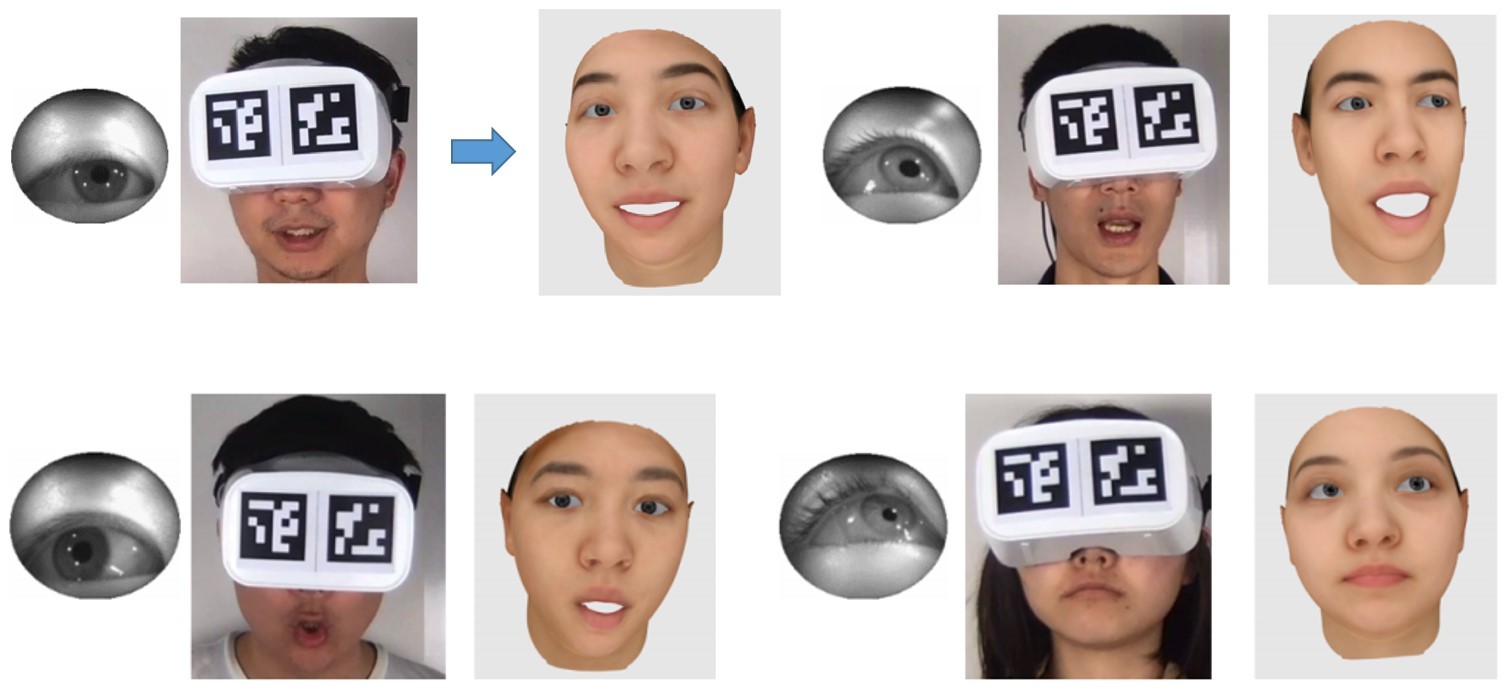
Wearing VR headsets is not directly suitable for bidirectional telepresence,
as the headset occludes the user's eyes and prevents eye contact between
multiple users. The system presented here virtually "removes" the headset; by
facial tracking and modeling a user's partially visible face, together
with input from in-headset eye cameras, a de-occluded user's face is automatically
generated.
Guoxian Song, Jianfei Cai, Tat-Jen Cham, Jianmin Zheng, Juyong Zhang,
Henry Fuchs, Real-time 3D face-eye performance capture of a person wearing VR headset,
ACM Multimedia Conference, Seoul, Korea, 2018.