Background
Our handling of conflicts of interest (COI) during reviewing of conference and journal submissions has changed very little although the number of submissions as well as number of PC members have increased exponentially for several venues in recent times. Each paper’s authors must manually declare all conflicts of interest. As top-tier conference program committees can easily have hundreds of members, it is prohibitively expensive for PC chairs with thousands of reviews to manage to double-check the accuracy and completeness of these manual declarations. Nor can reviewers reliably catch unreported conflicts. Hence, it is paramount to design a data-driven solution to address the issue of scale, completeness, and accuracy in COI declarations. Such solution naturally paves the way for a fairer review process that is paramount for any scientific endeavor. The recent article by Snodgrass and Winslett in CACM nicely articulate the need to relook our COI declaration and detection mechanisms. Furthermore, an ACM SIGMOD Blog post on COI management issues is available here.
It is a capital mistake to theorize before one has data.
- A. Conan Doyle
Adventures of Sherlock Holmes
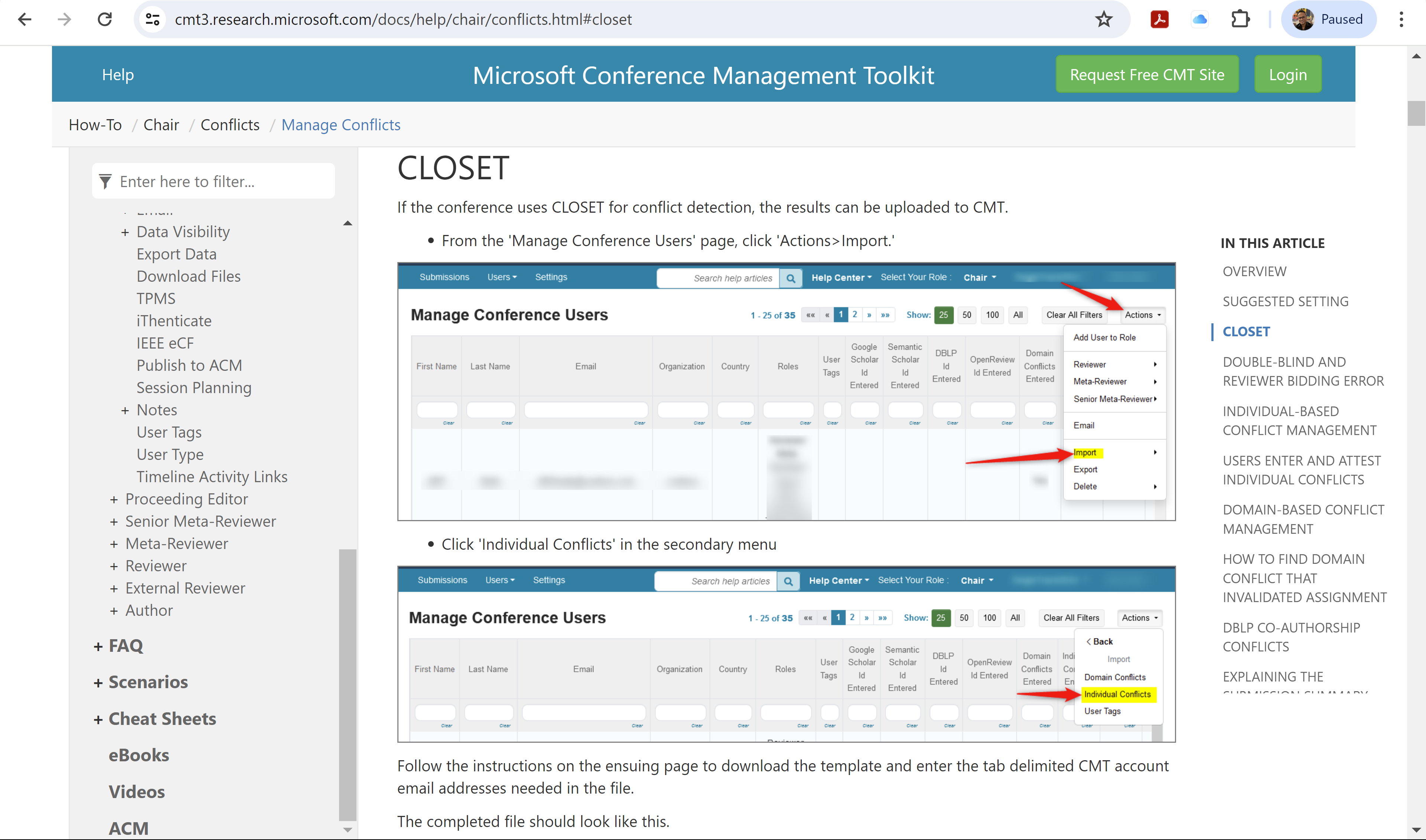
Overview of CLOSET
CLOSET is a state-of-the-art data science system to address the aforementioned challenges associated with COI management in peer-review venues. Specifically, it takes as input a list of submissions to a venue (paper id, paper title, and authors), reviewers and metareviewers assigned to these submissions, a list of PC/SPC members (name, institution, and email) of the venue, and an optional file containing author-specified COI. It generates COI violation details (if any) between the authors of submissions and assigned reviewers/metareviewers as output. CLOSET focuses on COI w.r.t the following three scenarios: (a) past coauthorship between authors and reviewers; (b) same institution of affiliation, and (c) submarine COI. In the case, the author-specified COI details are available, it also generates as output a set of authors (possibly empty) associated with each paper who have unreported COI with any reviewer (not limited to assigned reviewers) in the PC.
Note that CLOSET does not ingest any information about the content of a paper beyond its title. Also, it neither requires any details of review comments and ratings given by reviewers, nor demands any details from authors (e.g., google scholar page, names of collaborators). CLOSET is designed based on the principle that we should not demand additional inputs from authors and reviewers beyond those that are typically provided by them for any conference. Consequently, it does not require any changes to the existing interaction behavior of authors and reviewers with a review management system. It is also orthogonal to any reviewer assignment process (manual, automatic, or TPMS-based). That is, it does not care how reviewers are assigned to a paper.
CLOSET is implemented using Python and a relational database system. Under the hood, it exploits multiple bibliographic data sources and implements novel homonymy (i.e., disambuation) resolution and indexing and pruning strategies to make COI detection accurate, efficient, and scalable. It can also identify the correct author among those sharing identical names with him/her with high accuracy. It has in place a data cleaning framework and a name matching module that is cognizant of the ways authors typically specify their names in order to facilitate generation of highly accurate results. For instance, CLOSET can detect unreported COI that are missed by an exact name-based COI search technique. On the other hand, it will not detect false positives that may result from a very generic regular expression-based name matching. The output of CLOSET is presented in visual and structured text formats.
CLOSET also supports several additional features related to review management. It has a bid analytics component to analyse bids w.r.t COI. It can analyse reviewer assignments based on diversity and provide consolidated report to PC chairs. It facilitates analysis of PC performance w.r.t potential bias in the review process. Lastly, it can generate candidate COI-aware reviewer recommendation for each submission for PC chairs to exploit during reviewer assignment to submissions. To the best of our knowledge, none of these features are supported by existing industrial-strength review management systems.
Currently, CLOSET supports any venue hosted by Microsoft's CMT and Easy Chair. The framework is easily extensible to support other review management systems. Unreported COIs detected by CLOSET can be directly ingested by CMT to facilitate automatic reviewer assignment.
CLOSET enhances performance of COI detection by orders of magnitude in terms of efficiency and accuracy. PC chairs of several venues have attempted to identify COI manually which typically take them days. CLOSET can discover these COIs within minutes. More importantly, CLOSET can detect valid COIs that may evade manual detection.
CLOSET can also be used for auditing reviewer assignment data of past editions of conferences (i.e., post-facto).
How Can I Use CLOSET?
CLOSET is available as a paid service where a venue chair gives us access to the aforementioned information and we generate the COI details using it. In order to protect the security and privacy of COI detection code, CLOSET is not publicly downloadable. The pricing model of CLOSET is available here. The non-exhaustive list of venues that has used CLOSET can be viewed here.
Disclaimer
CLOSET and its variants do not use any machine learning/AI-based techniques for COI management. All results of CLOSET are based on hard data, explainable, and these explanations are shared in the final reports to the PC chairs.
Supported By


